云知声U2登顶LLM Stats综合榜前30,长上下文能力超越Claude Opus 4.7
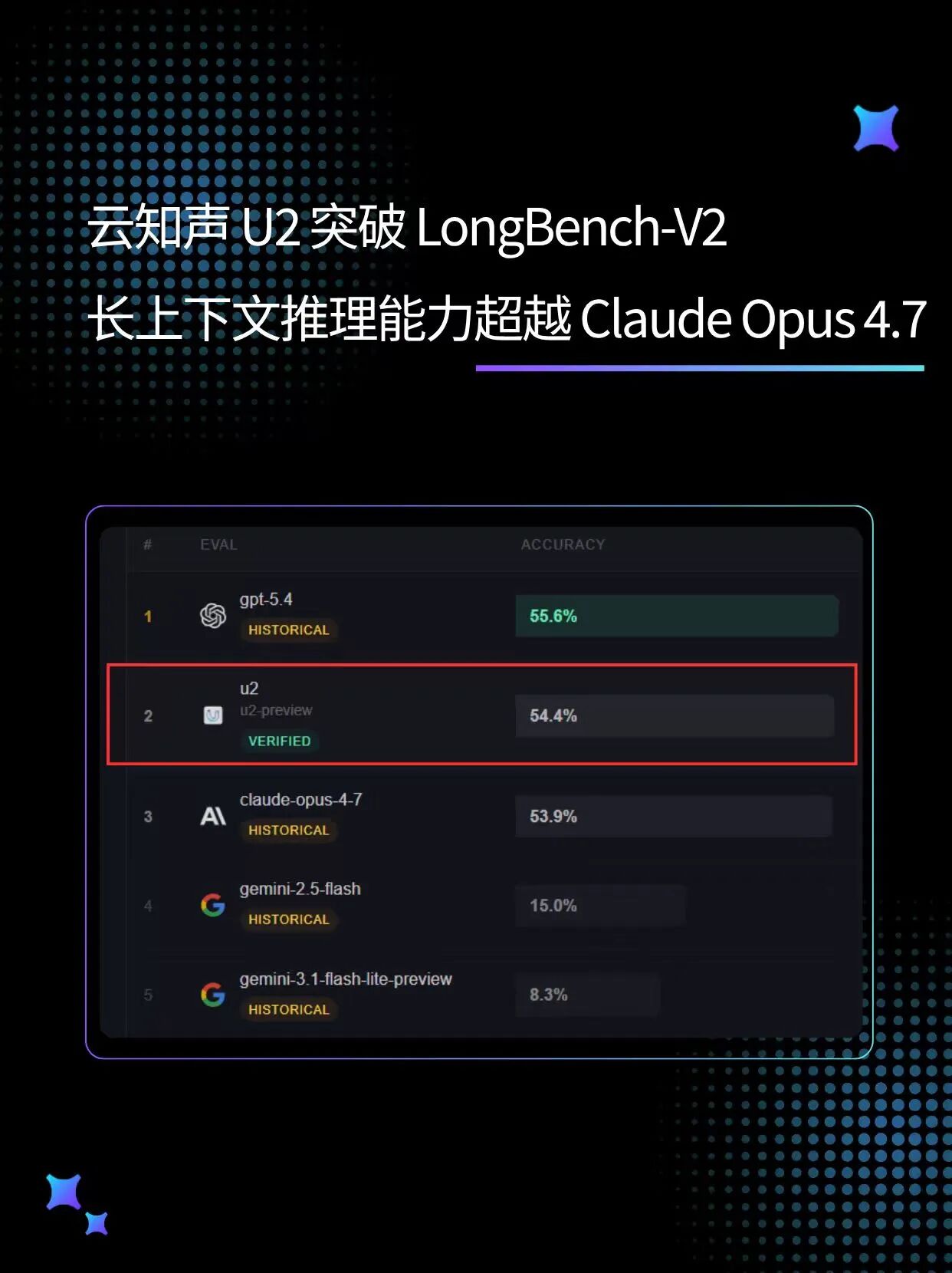
SmartHey6月10日消息,今日,海外权威AI模型评测平台LLM Stats更新最新榜单,国产大模型云知声U2表现亮眼:在LLM Stats Score综合能力榜单中跻身全球模型总榜前30,按厂商最佳模型成绩位列全球第九;同时,在独立长上下文评测基准LongBench-V2中,U2以54.4%的准确率(Accuracy)超越Claude Opus 4.7。
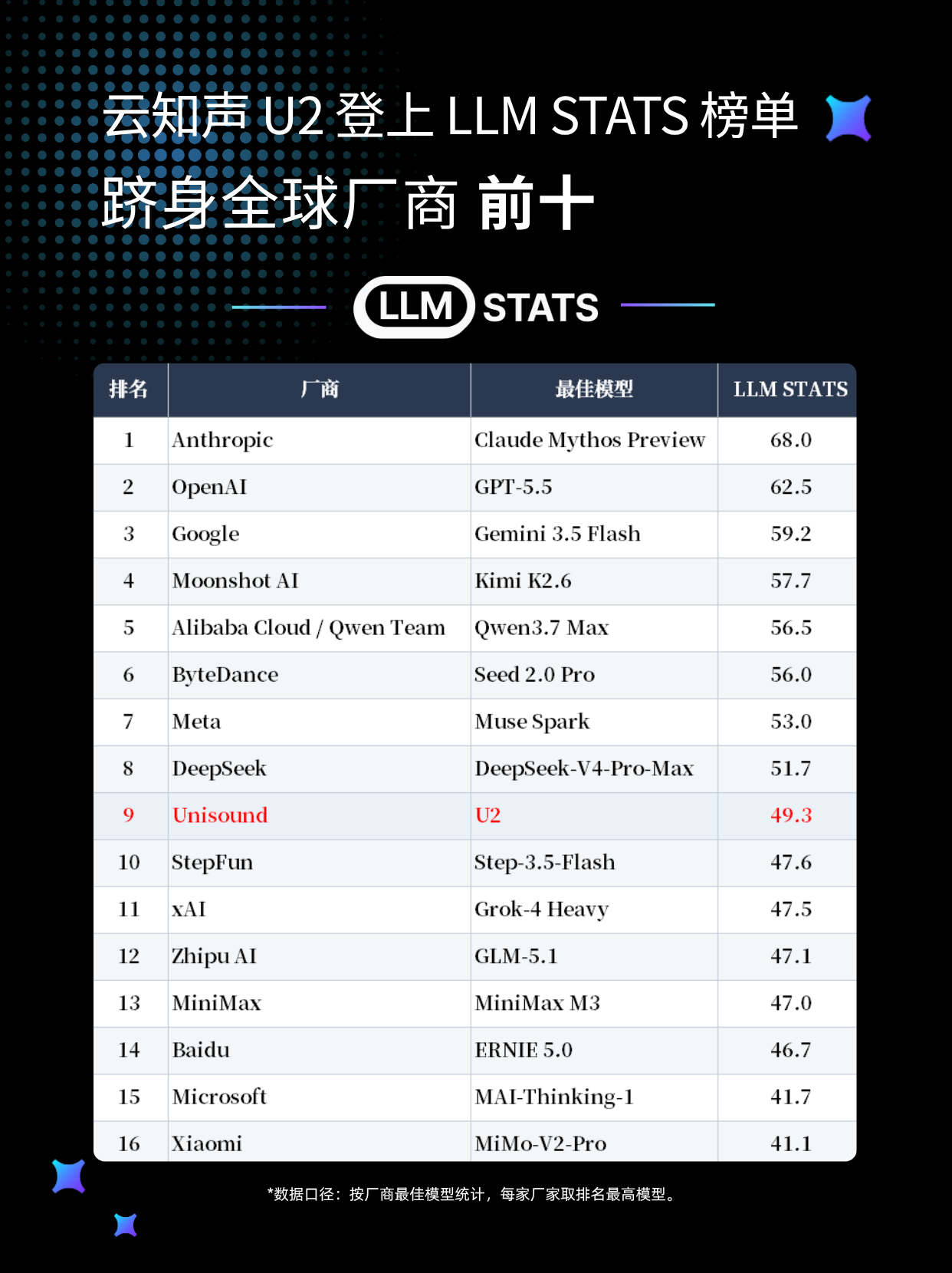
LLM Stats Score并非面向刷榜设计的单一测试集排名,而是一套面向真实工作负载构建的综合能力评分体系。其最终得分融合公开数据、独立采样实测结果及经严格验证的benchmark表现,力求客观反映模型实际可用性。
该评分体系覆盖推理、代码生成、知识理解、工具调用与智能体协作、长上下文处理等多个核心维度,更贴近对大模型综合实战能力的横向比拼。
LongBench-V2是当前长上下文推理领域公认的高难度评测基准之一。测试集包含503道多选题,上下文长度跨度达8K至200万词(2M words),并按short、medium、long三档长度区间分别评估;任务类型涵盖单文档问答、多文档问答、长上下文学习、长对话历史理解、代码库语义理解及长结构化数据解析六大场景,全面检验模型在不同规模上下文下的稳定性、一致性与深度理解能力。