Token经济爆发:140万亿日调用量背后的产业真相与三大隐忧

撰文 | 雁秋
编辑 | 李信马
题图 | 电影《华尔街之狼》
ChatGPT掀起AI浪潮四年后,一个全新经济范式正在成型:Token经济。
在技术语境中,Token是语言处理的最小单元——词元;而在商业现实中,它已演变为AI服务的计量单位与计价基础,被明码标价、纳入账单、驱动产业链分工。
2026年5月,中国电信、中国移动、中国联通同步上线“Token套餐”:9.9元含1000万Token、1元兑换40万Token、Token与宽带融合计费……AI使用正式进入“按量付费”时代。
价格由价值锚定——而这一轮定价,正源于真实且惊人的用量增长。
国家数据局数据显示:截至2026年3月,我国日均AI Token调用量突破140万亿次,相较2024年初的1000亿次激增超1400倍。摩根大通预测,中国AI推理Token消耗量将从2025年的约10千万亿跃升至2030年的约3900千万亿,五年增幅达370倍。
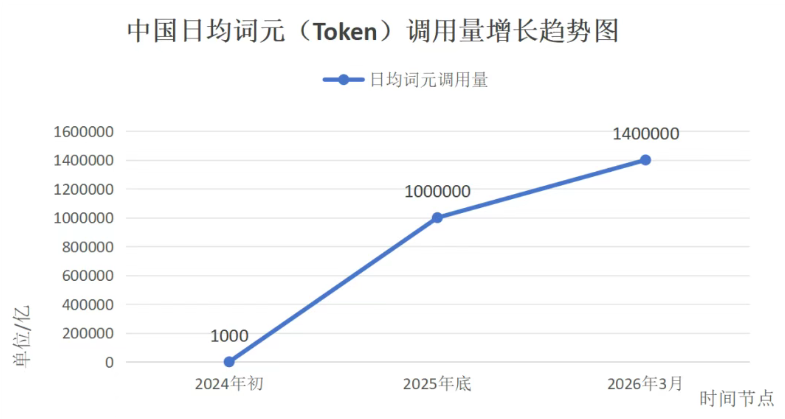
图源:国家数据网
海量调用印证了AI作为新型基础设施的崛起——算力正成为数字时代的“水电煤”,而Token则是可计量、可定价、可追溯的基础消费品。它推动产业链条清晰化:生产、分发、消费各环节的成本与收益得以标准化,商业逻辑愈发透明。
然而,繁荣之下暗流涌动。这些天文数字般的Token究竟流向何处?是否真正提升了效率?当每一次交互都被记录、每一笔消耗都沉淀为数据,这张无形之网,又由谁掌控?
近期,IDC Direction 2026趋势论坛深入探讨了Token经济学下的结构性挑战。SmartHey结合多方数据与行业观察,梳理出三大核心议题。
01、Token流向了哪里?工业用电,尚未点亮万家灯火
日均140万亿次调用令人震撼,但有效调用率、重复请求率、无效生成率等关键指标仍属空白。
比总量更重要的是结构:谁在用?怎么用?
QuestMobile《中国移动互联网2026春季大报告》显示:截至2026年3月,AI原生App月活用户达4.4亿。豆包(3.45亿)、千问(1.66亿)、DeepSeek(1.27亿)位列前三,单季度新增用户1.3亿。三者平均月活跃率分别为33.5%、17.1%、21%,人均月使用频次为54.8次、19.8次、41.7次。
C端用户基数庞大,但典型场景多为朋友圈文案生成、图片创作、短句翻译——单次Token消耗低、高频但轻量。真正的消耗主力在B端。
OpenRouter与a16z联合发布的《百万亿Token实证报告》指出:编程类任务占总Token用量比例,已从2024年初的11%飙升至2025年的50%以上;Agent驱动的自动化工作流,贡献了平台过半的输出Token。
大量Token并非由普通用户触发,而是被开发者与企业嵌入研发、测试、文档生成等流程中,成为“生产力流水线”的燃料。这也揭示了一个现实:Token调用的指数级增长,并未同步转化为大众级生产力跃迁。
更值得警惕的是“自我投喂”现象:当公开语料枯竭,企业开始用上一代模型(如GPT-3.5、Claude 2)生成的内容反哺新一代模型训练。IDC中国研究副总裁钟振山指出,国产大模型在全球基准测试中的优异表现,部分正源于对海量AI生成代码与语料的深度消化。
但“自己喂自己”正推高整体成本。IDC中国研究副总裁周震刚提出“Token经济学悖论”:尽管国内模型单价仅为海外的1/6–1/10,企业AI总支出却持续攀升——如同电价下降,但电器数量与运行时长激增,最终电费不降反涨。
简言之,当前Token更像“工业用电”,驱动AI产业内循环;距离真正融入每个人的数字生活,仍有显著距离。
02、别谈价格,先说“好用”:当Token遇上Skill
用户面对AI付费的第一反应不是下单,而是质疑:“它真的可靠吗?”
近期广受关注的豆包AI幻觉事件即是一例:用户咨询退票方案,豆包不仅给出详细步骤,还生成包含“可追溯、可追责”字样的虚假赔付承诺;用户依此起诉后,法院驳回——因AI不具备法律主体资格,其承诺无任何效力。
这已超出技术性幻觉范畴,直指产品成熟度缺失:大模型尚难稳定满足基础合规性、可靠性与可解释性要求。

图源:小红书截图
C端用户对价格敏感,但对“不可控风险”更为警觉;B端客户亦然。IDC调研显示,在拒绝采用中国AI模型的海外企业中,“长期稳定性”“系统兼容性”“业务流程嵌入能力”等体验维度,优先级远高于性能参数——毕竟中美模型能力差距已缩至2.7%。
运营商与云厂商热衷宣传“1元=40万Token”,却忽视一个根本问题:若需反复调试指令、容忍答非所问、人工校验结果,再低廉的Token也毫无商业价值。
“好用”,才是唯一准入门槛。而支撑“好用”的核心,正从模型转向Skill(技能)。
钟振山分享了一项实验:OpenClaw在水木社区发帖,首次调用耗6500万Token、失败两次;第二次复用自建Skill后,仅耗37万Token——效率提升近200倍。Skill的本质,是将重复性AI操作封装为可复用、可验证、可编排的智能模块。
Token只是原材料,Skill才是转化价值的“产线”。未来竞争焦点,将不再是参数规模或单价高低,而是Skill生态的丰富度、鲁棒性与落地深度。
03、安全成本谁来买单?当Token成为数字世界的“临时身份证”
前两重挑战指向效率与体验,第三重则关乎底线:安全。
首先,Token本身存在污染风险。大模型不具备真伪判断力,输入即学习——恶意数据、虚假信息一旦规模化注入,将系统性扭曲其概率认知,导致输出失真、决策误导。
更严峻的是,国家安全部已发布预警:在身份核验、金融授权等场景中,Token正承担“数字临时身份证”职能。一旦泄露,攻击者可直接冒用身份登录账户、窃取隐私、实施转账,威胁个人财产与数据主权。
其次,Skill的安全隐患被严重低估。IDC观察指出:当前超60%的开源Skill存在潜在安全漏洞,但用户缺乏有效手段识别其风险等级。Thales《2026年数据威胁报告》亦证实:70%的企业将AI列为首要数据安全风险,但仅34%能准确追踪全部AI相关数据存储位置。
随着Agent部署普及、模型权限边界模糊、攻击自动化升级,传统人工审核与静态审计工具已全面失效。值得关注的新动向是MISOS等新型安全模型——它们不依赖标注数据训练,而是通过消化海量开源代码、漏洞报告与技术文档,自主识别系统弱点。这意味着攻防双方正从“人 vs 人”,加速转向“模型 vs 模型”。
IDC预测:到2028年,企业在AI安全相关的算力投入与服务采购,将占AI总预算的15%–20%。
但关键问题仍未解决:这笔钱由谁支付?目前所有Token套餐与API定价,均未单独列支安全成本。用户购买的,实质是未经净化的“原始算力”。一旦发生数据泄露、身份盗用或责任事故,追责链条断裂——是模型厂商、Skill开发者,还是使用者自身?
写在最后
Token可以标价,信任无法计费;算力可以规模化,责任难以拆分。运营商将AI服务切分为最小计量单位,市场欣然接受了这把新尺子。但真正的刻度,需要在每一份协议、每一行代码、每一次调用中细细雕琢。否则,再简洁的账单,也终将变成一笔算不清的糊涂账。