百川智能发布医疗大模型Baichuan-M4:HealthBench三大榜单全球第一,幻觉率低至3.3%
SmartHey6月22日消息,据百川智能公众号披露,百川智能联合清华大学研究团队正式发布新一代医疗增强大模型——Baichuan-M4。该模型在权威医疗评测体系HealthBench及其Hard(复杂临床决策)、Professional(专业能力)两大子榜单中均位列世界第一,综合性能全面超越GPT-5.5、Claude Opus 4.7与DeepSeek-V4-Pro;事实性幻觉率低至3.3%,为当前行业最低水平。
从M1到M4,百川始终聚焦同一目标:跨越AI‘会答题’与‘会看病’之间最关键的临床鸿沟。
HealthBench全球第一:不止高分,更重临床实效
在OpenAI主导构建的国际公认医疗评测基准HealthBench中,Baichuan-M4以综合得分68.6位居榜首,领先第二名GPT-5.5超10分;在最具挑战性的Hard子集(模拟真实重症决策场景)中,领先幅度达15.9分。
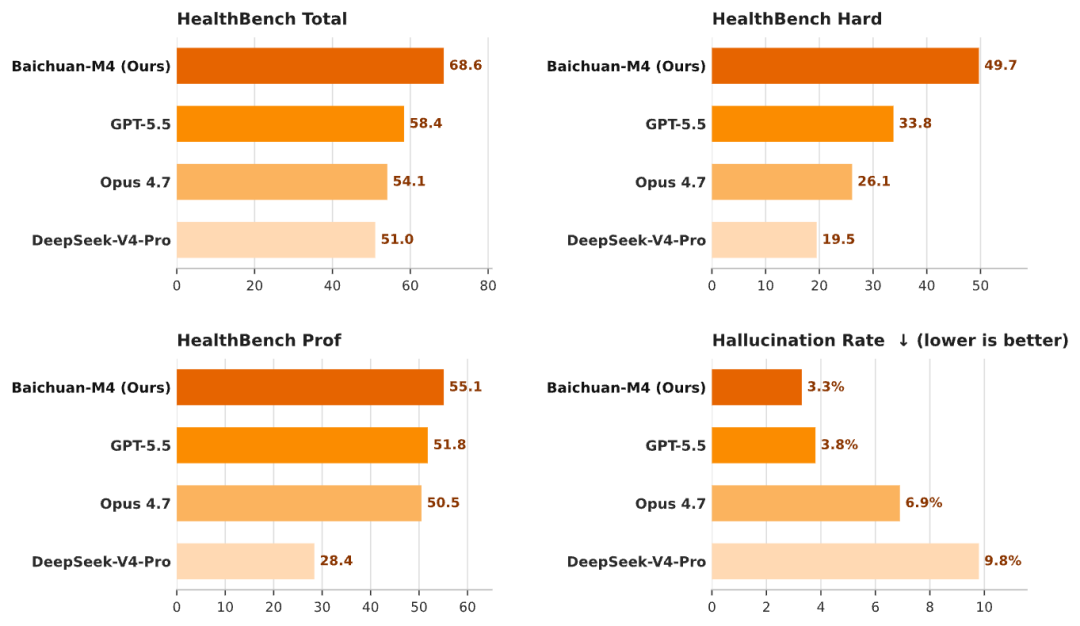
其事实性幻觉率仅为3.3%,显著低于GPT-5.5(3.8%)、Claude Opus 4.7(6.9%)及DeepSeek-V4-Pro(9.8%)。这些数字背后,是四项深度贴合临床工作流的核心能力:主动问诊、全病程记忆、循证锚定与自主调度。
深度问诊:像资深医生一样层层追问
问诊是诊疗的起点,也是判断医生专业度的关键环节。优秀临床医生善于通过结构化追问,将患者零散、模糊甚至自我忽视的症状,梳理成完整、可分析的病程线索。
而通用大模型常依赖提示词“扮演医生”,几轮提问后便急于下结论。现实中,“胸口闷、偶尔心慌”可能是焦虑,也可能是急性心梗前兆——唯有持续追问诱因、性质、时长与伴随症状,才能准确鉴别。
Baichuan-M4具备主动追问机制:优先识别危急重症信号,动态调整问题路径,不跳过关键病史,也不因信息不全而强行作答。
例如,一位用户深夜因脚痛求助,M4通过十轮精准问询(涉及具体脚趾、疼痛时长、外伤史、饮酒情况、既往血尿酸水平等),逐步锁定急性痛风可能,建议其就诊风湿免疫科,并自动生成结构化问诊卡片。患者持卡就医后,经医生复核与检查,确诊结果与M4初步判断高度一致。
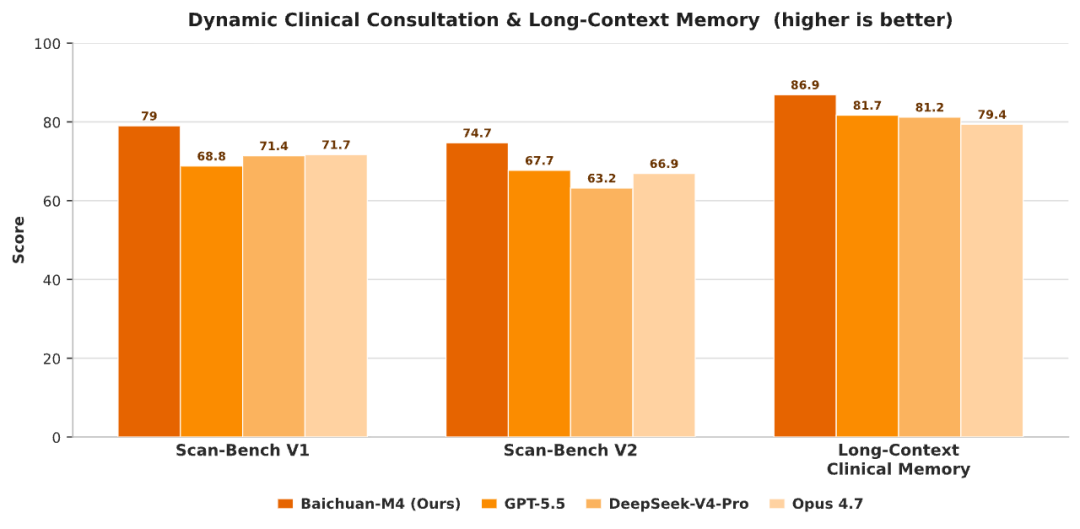
为科学评估这一能力,百川联合150余位一线临床医生,基于医学教育经典OSCE(客观结构化临床考试)范式,构建动态问诊评测体系SCAN-bench。该体系不考静态知识,而是全程模拟真实接诊—分析—诊断闭环。在SCAN-bench中,M4初诊得分为79.0、复诊74.7,均大幅领先GPT-5.5、DeepSeek-V4-Pro与Claude Opus 4.7。
全病程记忆:记住一个人,而不只是一次对话
真实诊疗极少止步于单次问诊。化验结果、用药反应、新发症状……都会随病情演进不断修正医生判断。这意味着:能持续追踪个体完整健康轨迹的系统,才真正具备连续诊疗能力。
通用大模型的“记忆”通常限于短期对话上下文,难以跨时段整合历史病历、检验趋势与用药反馈。它记得住一轮对话,却记不住一个活生生的人。
M4首创「全病程记忆」机制,打通多源健康数据:历史电子病历、多次问诊记录、动态检验指标、药物疗效反馈等,在长周期交互中始终维持对患者个体画像的完整认知。在长上下文临床记忆专项评测中,M4取得86.9分,为同类模型最高,较上一代M3提升21.1分。更重要的是——当模型真正掌握个体全貌,其决策便不再是模板化输出,而是因人制宜的精准干预,这正是实现个性化医疗的技术基石。
例如,一位异地生活的用户在家庭群中得知老人“走一圈就喘”,M4结合其多年血压、心电图、BNP等健康档案与既往心衰风险因子,主动预警早期心功能不全可能,并建议及时专科评估。后续医院检查证实该判断准确。
证据锚定:每一句结论,都可溯源至原文段落
循证医学的核心信条是:可信度不取决于语言是否专业,而取决于结论是否有权威、精确、可追溯的证据支撑。
当前多数医疗模型虽已支持文献引用,但实践中常出现两类问题:一是编号与文献不匹配;二是文献正确,但所引段落与结论逻辑脱节。
为此,百川提出“证据锚定”标准——要求模型生成的每一条医学陈述,必须精准绑定至原始指南、共识或论文中的**具体段落编号或原文摘录**,而非仅标注文献标题。其底层采用六源循证范式,严格限定数据来源为中华医学会指南、WHO文件、NEJM/Lancet核心论文等六大权威渠道,杜绝开放网络抓取。
在此基础上,M4进一步将临床知识解构为标准化、可复用的“临床路径单元”,目前已覆盖200余种疾病、超1000个路径节点,全部由三甲医院资深专家定义并持续校验。
在百川自建循证评测基准Baichuan-EBM中,M4循证引用精度达90.0,远高于GPT-5.5(54.7)与OpenEvidence(55.9)。
Agent架构:自主调度,闭环诊疗
问诊、记忆、循证若彼此割裂,再强的单项能力也无法构成可用系统。传统方案多依赖人工编排调用顺序,但患者不会按模块提问——衔接错位,系统即告失效。
百川为此打造专属医疗智能体中枢——Baichuan-Harness。如果说M系列模型是医疗AI的大脑,Harness便是它的自主神经中枢:它实时判断何时追问、何时检索证据、何时调取病史,并在安全约束下完成工具调用与任务拆解。面对复杂任务(如整合五年检验报告+多轮用药反馈),Harness可自动并行处理子任务,确保模型始终聚焦于整体诊疗路径推理。
尤为关键的是,该系统具备真实场景进化能力:线上疑难案例、用户追问、医生纠偏等数据,经严格脱敏与归因后回流训练闭环,驱动模型持续优化。由此,四大能力被有机整合为统一诊疗智能体,M4也真正从“最强医疗大脑”,跃升为可独立执行连续诊疗的医疗AI助手。
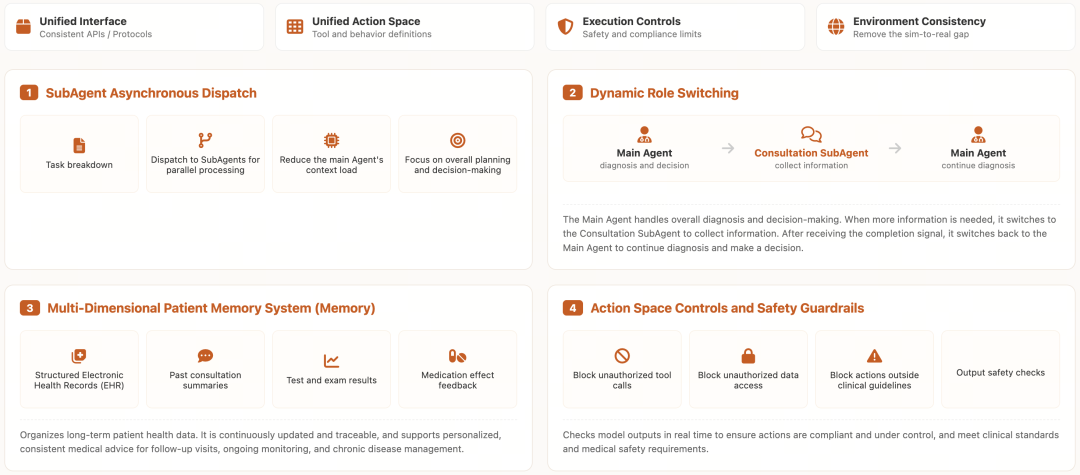
Baichuan-Harness 医疗智能体架构图
从OpenAI的ChatGPT Health到Anthropic的Claude for Healthcare,全球顶尖AI力量正加速涌入严肃医疗赛道。而在这片对可靠性、安全性与临床贴合度要求最高的深水区,百川M4交出了迄今最扎实的答卷:HealthBench三大榜单全面登顶、幻觉率行业最低、循证精度断层领先、多轮问诊能力持续突破。
从M1到M4,百川只做一件事:让AI真正学会看病。
这件事极难,却也最有价值——它正将原本稀缺的优质诊疗能力,转化为触手可及的普惠健康服务。