谷歌发布Gemma 4系列开源大模型:首创“单位参数智能水平”,覆盖端侧到云端全场景
SmartHey4月3日消息,今日,谷歌正式推出 Gemma 4 大模型,据称是迄今为止谷歌最智能的开源模型。Gemma 4 专为高级推理与智能体工作流打造,实现了前所未有的“单位参数智能水平”。

本次谷歌推出四种规格的 Gemma 4 通用模型:高效 20 亿参数版(E2B)、高效 40 亿参数版(E4B)、260 亿混合专家模型(MoE)与 310 亿稠密模型(31B)。全系产品均突破简单对话边界,可高效处理复杂逻辑推演与端到端智能体工作流。
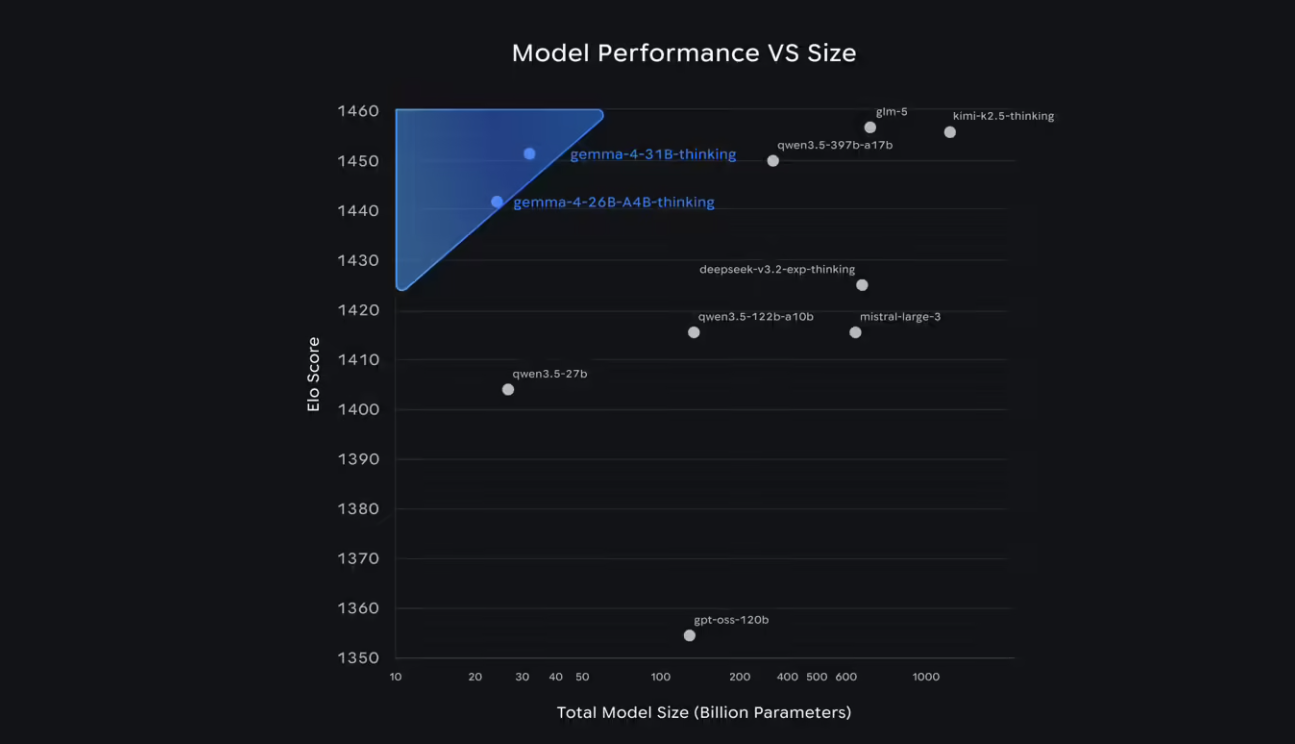
其中大参数量级模型在同规模下实现顶尖性能:31B 模型目前在行业权威 Arena AI 文本榜单中位列全球开源模型第三,26B 模型位居第六;更值得关注的是,Gemma 4 在多项基准测试中的表现甚至超越参数规模达其20倍的竞品模型。对开发者而言,这种突破性的单位参数智能效率意味着——仅需更低的硬件投入与算力成本,即可部署前沿级AI能力。
在端侧设备上,E2B 与 E4B 模型重新定义了本地AI部署的价值主张:不再依赖参数堆砌,而是聚焦多模态理解、亚百毫秒级低延迟响应,以及与安卓、Linux、Raspberry Pi等主流生态的深度无缝集成。
以下是 Gemma 4 模型系列的核心优势:
高级推理:支持多步规划、因果链分析与深度符号逻辑,在数学证明、复杂指令分解等高难度基准中显著领先前代。
智能体工作流:原生支持函数调用、结构化 JSON 输出及可编程系统指令,开箱即用构建能自主调用工具、连接API并稳定执行多步骤任务的智能体。
代码生成:提供高质量离线代码补全与生成能力,将普通工作站升级为轻量、隐私优先的本地AI编程助手。
视觉与音频:全系列原生支持图像、视频理解与可变分辨率适配,在OCR、图表解析、文档结构识别等视觉任务中表现优异;E2B 与 E4B 更集成原生音频输入模块,支持实时语音识别与语义理解。
更长上下文:端侧模型支持最高128K tokens上下文窗口,大模型可达256K,轻松容纳整份技术文档、大型代码库或长篇法律文本。
140 + 种语言:基于超140种语言原生语料训练,覆盖小语种及低资源语言,助力全球化AI应用开发。
26B 与 31B 模型
专为研究者与开发者在通用硬件上释放顶尖推理性能而优化:非量化bfloat16权重版本可在单张80GB英伟达H100 GPU上高效运行;量化版本则全面兼容消费级显卡(如RTX 4090),适用于IDE插件、编程辅助工具及轻量智能体服务部署。
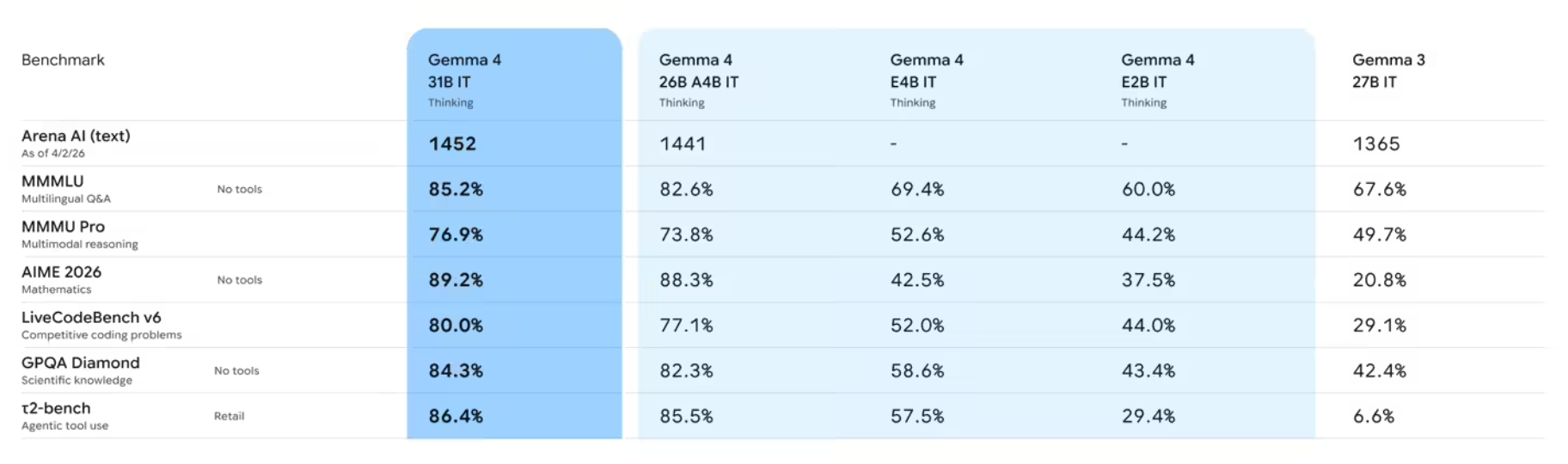
26B 混合专家模型(MoE)采用稀疏激活机制,推理时仅动态调用约38亿参数,兼顾高吞吐与极低首字延迟;31B 稠密模型则以完整参数容量提供最强基础性能,为微调、领域适配与科研实验提供坚实底座。
E2B 与 E4B 模型
从架构设计即面向极致能效:实际推理参数严格控制在20亿与40亿以内,大幅降低内存占用与功耗。通过与谷歌Pixel团队、高通、联发科等厂商深度协同,已实现在智能手机、树莓派5、NVIDIA Jetson Orin Nano等主流端侧设备上完全离线、近零延迟运行。安卓开发者现可通过AICore开发者预览版快速构建智能体流程,并获得与Gemini Nano 4的向前兼容支持。