智谱发布GLM-5.1:全球最强开源大模型,首超Claude Opus 4.6,实现8小时长程自主编程
SmartHey4月8日消息,智谱今日正式发布新一代开源大模型 GLM-5.1,官方宣称其为当前全球性能最强的开源模型。据披露,GLM-5.1 是首个支持连续运行达 8 小时的开源模型,在最贴近真实软件开发环境的 SWE-bench Pro 基准测试中,首次实现国产模型对 Anthropic Claude Opus 4.6 的超越。
OpenRouter 数据显示,伴随本次发布,智谱 GLM 系列 API 费用整体上调 10%。调价后,GLM-5.1 在 Coding 场景下的缓存命中 Token 单价已逼近 Anthropic Claude Sonnet 4.6 水平——这也是国产大模型首次在核心应用场景达成与国际头部厂商的价格对标。
官方详细说明如下:
从 3 分钟的 Vibe Coding(氛围编程),到 30 分钟的 Agentic Engineering(智能体工程),再到此次突破性的 8 小时 Long-Horizon Task(长程任务),GLM-5.1 在任务持续性与自主性上实现全新跃升。
GLM-5.1 是智谱迄今最智能的旗舰开源模型,亦是目前综合能力最强的开源大模型。其代码生成与工程执行能力显著增强,尤其在长程复杂任务中表现突出:区别于传统以分钟为单位交互的模型,GLM-5.1 可在单次指令下独立规划、分步执行、动态反思并持续优化,全程无需人工干预,最终交付完整、可运行的工程级成果,最长可持续工作超 8 小时。
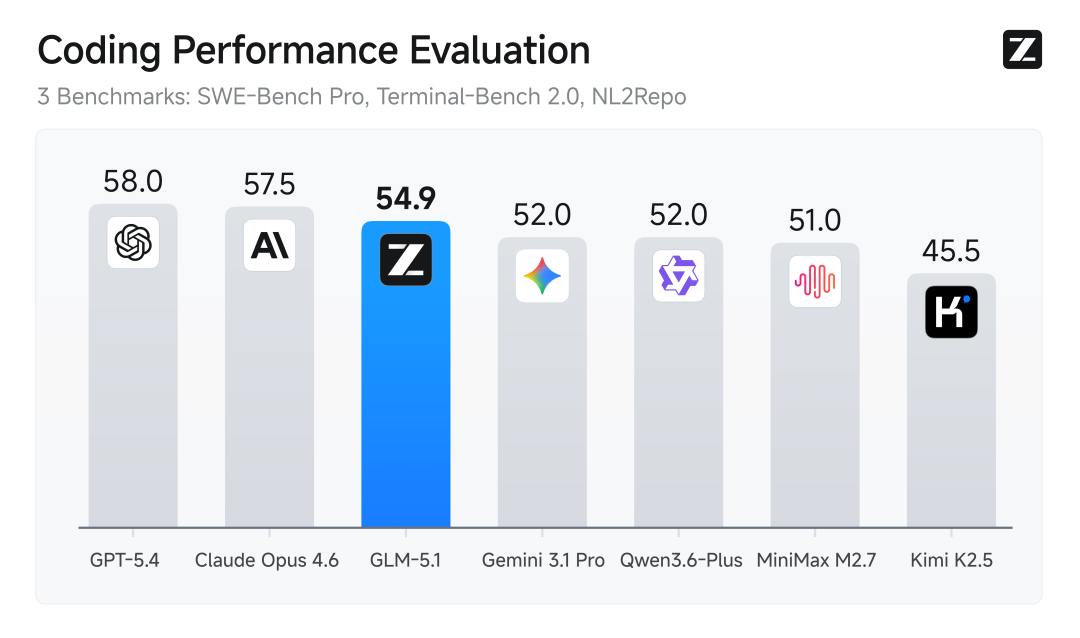
代码能力被视为衡量大模型真实智能水平的关键标尺。下图汇总了业界三大权威代码评测基准的平均得分,涵盖专业软件开发能力评估的 SWE-Bench Pro、命令行问题解决能力的 Terminal-Bench 2.0,以及从自然语言零起点构建完整代码仓库的 NL2Repo。结果显示,GLM-5.1 综合排名全球第三、国产第一、开源模型第一。
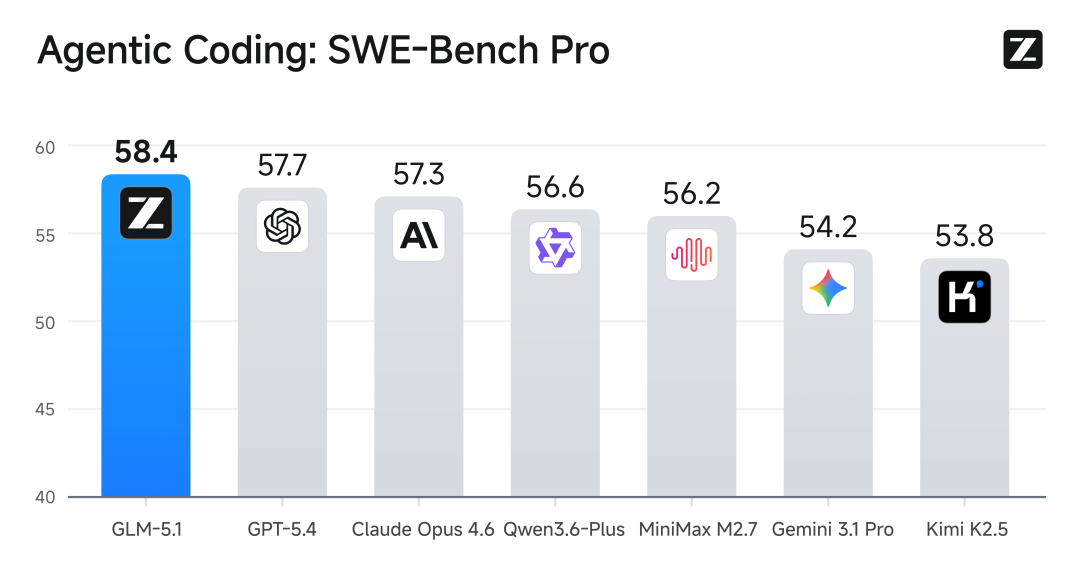
在最具挑战性的 SWE-bench Pro 测试中,GLM-5.1 刷新全球纪录,超越 GPT-5.4 与 Claude Opus 4.6。该基准要求模型在真实的 GitHub 开源项目中精准定位、分析并修复高复杂度工程级 Bug,被公认为检验大模型能否胜任实际软件开发工作的“黄金标准”。