DeepSeek-V4预览版正式开源:支持100万字超长上下文,Pro/Flash双版本矩阵亮相
SmartHey4月24日消息:今日,深度求索(DeepSeek)正式发布全新大模型系列 DeepSeek-V4 预览版,并同步开源。该系列首次实现 100万字(1M)超长上下文原生支持,在智能体(Agent)协同能力、世界知识覆盖度及复杂逻辑推理性能上,均达到国内领先、开源领域第一的水平。即日起,用户可通过官网 chat.deepseek.com 或官方 App 直接体验;开发者亦可仅通过更新 API 参数,无缝接入新模型。

双版本策略:Pro 专注全能旗舰,Flash 聚焦高效轻量
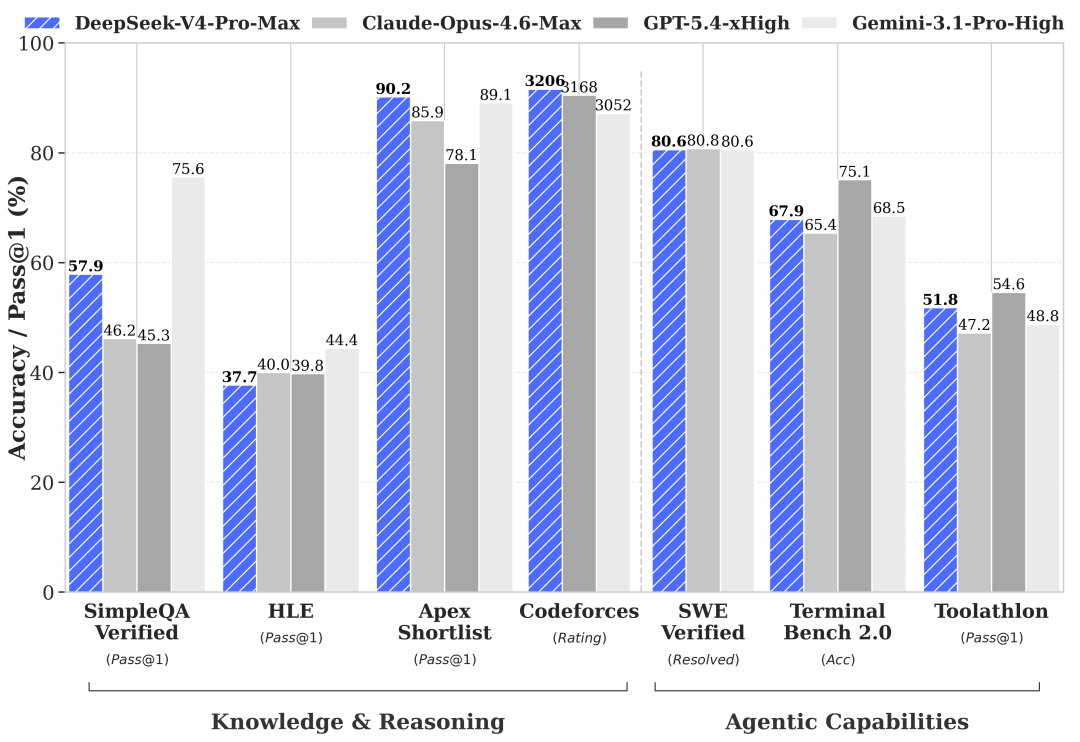
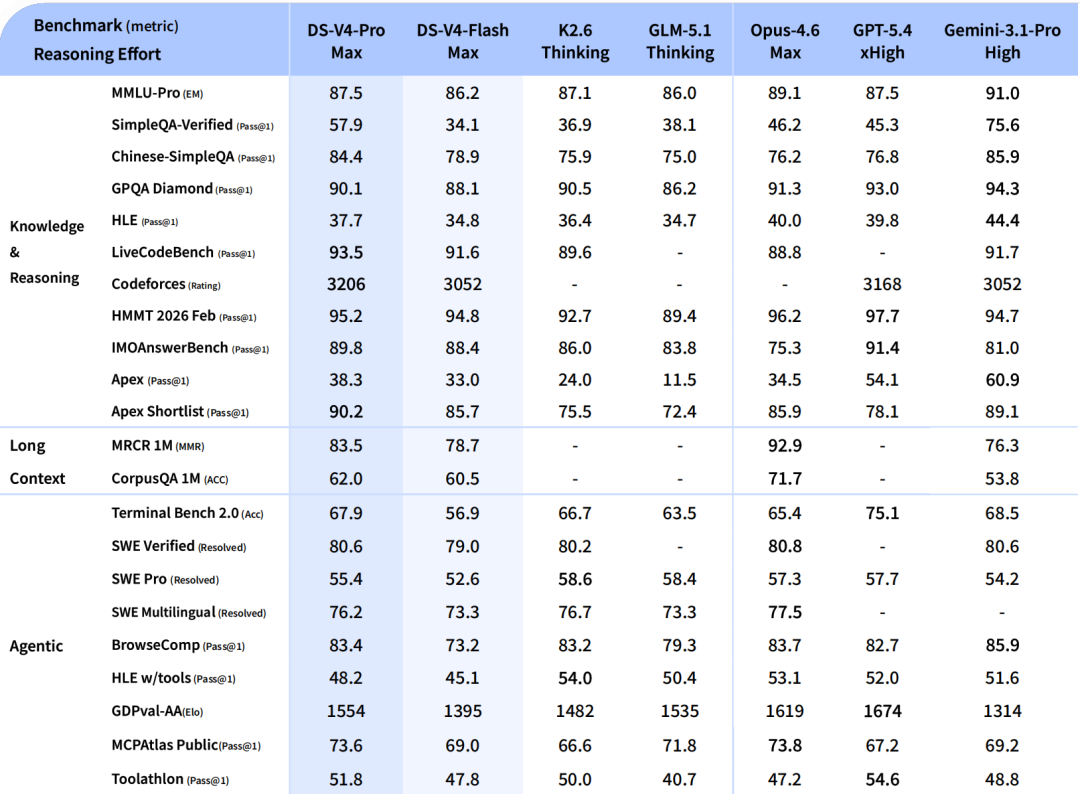
为适配差异化应用场景,DeepSeek-V4 推出 Pro 与 Flash 两大版本:
- DeepSeek-V4-Pro(高性能旗舰版):Agent 能力全面跃升,在权威 Agentic Coding 评测中位列开源模型首位;实际交付代码质量已逼近顶尖闭源模型 Opus 4.6(非思考模式),综合交互体验优于 Sonnet 4.5;在世界知识测评中大幅领先其他开源模型,仅略低于 Gemini-Pro-3.1;数学、STEM 及竞赛级编程任务表现超越所有已公开开源模型,推理能力比肩全球顶级闭源产品。
- DeepSeek-V4-Flash(高效经济版):在参数量与激活规模上进一步精简,推理能力与 Pro 版高度接近,世界知识覆盖略有收敛。得益于更低的计算资源需求,V4-Flash 提供响应更快、成本更优的 API 服务;在常规 Agent 任务中表现与 Pro 版基本一致,复杂多步协同任务仍有持续优化空间。
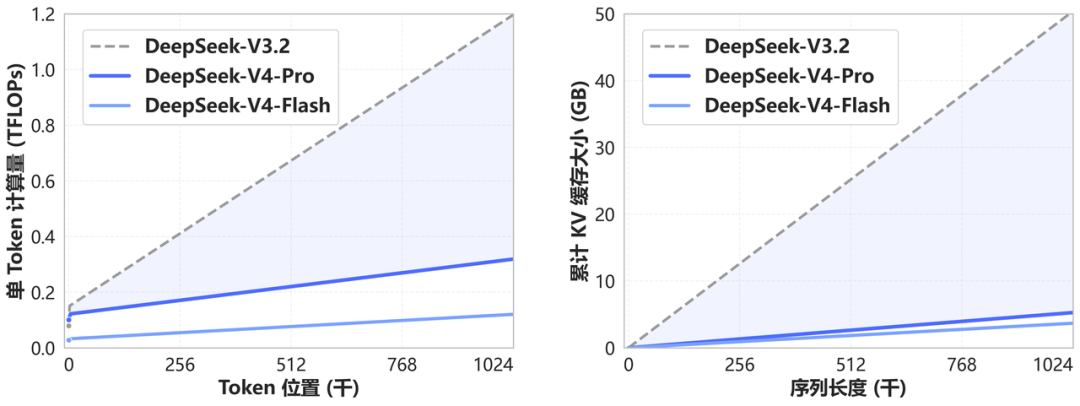
架构革新:首创 Token 压缩 + DSA 稀疏注意力,1M 上下文全面标配
DeepSeek-V4 在底层架构层面取得关键突破——融合自主研发的 Token 维度注意力压缩机制 与 DSA 稀疏注意力(DeepSeek Sparse Attention) 技术,有效缓解长上下文场景下的显存占用与计算延迟问题。相较传统长文本处理方案,该架构在保障百万级上下文吞吐效率的同时显著降低硬件开销。DeepSeek 官方明确表示:1M 超长上下文将作为 DeepSeek 所有官方服务的默认标准配置,即刻生效。
生态协同升级:深度适配主流 AI Agent 框架,强化结构化任务能力
围绕 AI Agent 开发范式演进,V4 系列已完成对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流框架的深度集成与调优。在自动化代码生成、多步骤任务编排、结构化内容输出(如 PPT、技术报告、会议纪要等)等典型 Agent 场景中,任务成功率与输出质量均有显著提升。