数据即燃料:亚马逊云科技详解AI时代的数据治理“黄金三角”

撰文 | 李信马
题图 | AI生图
在生成式AI加速落地的今天,数据已跃升为驱动企业智能化转型的核心生产要素——没有高质量、可治理、易调用的数据,再先进的大模型也难以为业务创造真实价值。
SmartHey2月12日消息:在近日于北京举行的媒体沟通会上,亚马逊云科技成长型企业及新兴业务总经理倪殿令系统阐释了数据治理在AI时代的关键地位。他指出,数据引擎与治理体系正构成亚马逊云科技面向生成式AI时代的两大核心能力,也是企业实现数智化跃迁不可或缺的底层支撑。

拍摄:SmartHey
为帮助理解复杂的数据处理逻辑,倪殿令以“智慧餐馆”作喻:后厨采购食材(原始数据)后,需清洗、分拣、切配——这一过程正对应Amazon EMR对海量非结构化数据的标准化治理:去噪、归一、向量化,使其成为适配AI模型的“精加工原料”。
“向量”恰如采购回的生鲜蔬菜:要炒土豆丝,就切丝;要做番茄炒蛋,就切块。数据预处理必须紧扣下游AI任务的实际需求,而非“一刀切”地泛化处理。

加工完成的“食材”被分类存入智能冰箱——即支持高效相似性检索的向量数据库。Amazon Aurora、Amazon RDS与Amazon OpenSearch等服务,正是这台“AI冰箱”的核心技术底座,确保向量数据按语义聚类、低延迟调取。

当用户发起一次AI查询(如客服提问或报告生成),系统便如厨师开冰箱取料、精准配伍、快速出菜——整个过程高度依赖底层数据组织的合理性与响应效率。

“决定生成式AI成败的关键,不在前端炫目的模型或应用界面,而在于后台的数据处理能力、向量存储架构与数据质量水位。”倪殿令强调,“在实际AI工程中,数据层贡献了超90%的效果差异。模型‘幻觉’的多少,本质上由企业自有数据的规模、覆盖度与准确性所决定。”
下图直观呈现了企业级AI数据实施路径,揭示数据如何从资源转化为差异化竞争优势:
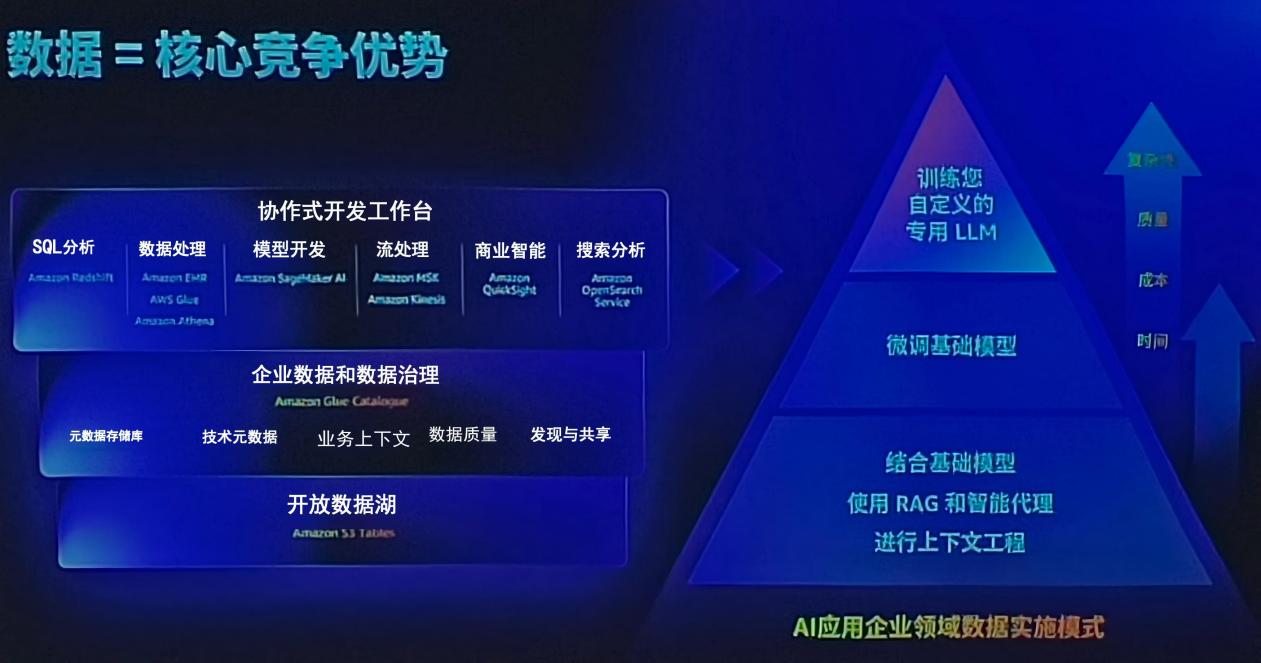
拍摄:SmartHey
图中右侧展示典型AI应用栈:底层是基础大模型,之上叠加RAG增强检索。但当RAG响应迟滞或精度不足时,企业往往需启动模型微调(Fine-tuning)。倪殿令比喻道:“如同一个人完成通识教育(预训练)后进入企业,需接受行业专属上岗培训——微调正是让通用模型深度理解企业语境、业务规则与知识体系的关键一步。”

而“知识蒸馏”则进一步聚焦:在试用期由资深导师将经验精华浓缩传授,使新人快速掌握高价值决策模式——这对应于在特定业务场景下,用小样本高质量数据提炼轻量、高准模型,实现敏捷部署与低成本迭代。

图中左侧则勾勒出数据价值转化全链路:原始非结构化数据 → Amazon EMR治理 → 向量化 → 向量数据库存储 → 模型调用闭环。倪殿令特别提醒:“多数企业使用的开源或商用模型终究是‘别人的’,唯有扎根自身业务沉淀的数据资产,才是构建AI护城河的根本。”

面向企业管理者,倪殿令提出拥抱生成式AI的“黄金三角”方法论:场景、数据、人才三者缺一不可。
其一,锚定高价值场景:聚焦智能客服、动态知识库、合规文档生成、营销内容创作等输入输出明确、ROI可衡量的业务切口,避免陷入技术空转;
其二,夯实数据基座:优先建设结构化数据治理能力,再通过向量化与向量数据库打通非结构化数据,形成“采集—治理—存储—调用”一体化数据引擎;
其三,构建复合型团队:既需数据工程师保障管道畅通,也需算法工程师完成模型适配与持续调优,更需懂业务的AI产品经理推动价值闭环。
值得注意的是,在IDC最新发布的《IDC MarketScape:中国面向生成式AI的数据基础设施2025年厂商评估》中,亚马逊云科技位列“领导者”象限,印证了其在数据治理领域的技术积累与产业实践深度。
数据治理已不再仅是IT部门的技术议题,而是关乎企业AI战略成败的战略支点。随着生成式AI从概念验证迈向规模化落地,围绕数据质量提升、向量工程优化、治理自动化等方向的技术创新将持续涌现,为企业释放更稳定、更可信、更可持续的AI生产力。
注:文中图片来自现场拍摄(经技术修正)及AI生成