云知声发布Unisound U1-OCR:全球首个工业级文档智能基座,正式开启OCR 3.0时代
SmartHey2月26日消息,就在刚刚,云知声正式推出 Unisound U1-OCR 文档智能基础大模型。作为全球首个面向工业落地的文档智能基座,该模型以“性能SOTA、可信可验、开箱即用、高效部署、强适配”五大核心能力,突破传统OCR技术边界,推动文档处理从“识别文字”迈向“理解语义与业务逻辑”的全新阶段。
技术跃迁:从OCR 1.0到OCR 3.0的范式升级
文档智能(Document Intelligence)是利用AI自动解析、理解并结构化处理各类文档图像的关键技术,涵盖版面分析、文字识别、语义理解与关键信息抽取等全流程任务。
早期OCR 1.0方案(如CRNN)仅聚焦字符级识别;进阶的OCR 2.0(以视觉语言模型VLM为代表)实现了端到端的版面感知与图文联合建模;而Unisound U1-OCR则定义并引领OCR 3.0——在精准还原物理布局的基础上,深度建模文档的层级结构、逻辑关系与业务语义,完成从“看见文字”到“读懂文档”的质变跨越。
国际领先:四大权威评测稳居SOTA榜首
Unisound U1-OCR是当前文档智能领域综合性能最强的基础模型之一,其创新性ViT+LLM混合架构融合了NaViT动态分辨率视觉编码器与3B规模语言理解模块,在计算效率与深层语义建模之间取得卓越平衡。模型核心突破包括:
✅ 语义驱动的动态阅读策略:摒弃机械顺序扫描,首创“先构建语义地图、再按需聚焦内容”的人类式阅读范式,自动识别标题、图表、正文等元素的逻辑从属关系,即便面对排版混乱的极端文档,仍能保持结构清晰、提取准确。
✅ 强化空间感知能力:通过高精度空间对齐模块与动态分辨率技术,深度融合文本坐标、相对位置与视觉上下文,彻底解决图文混排、密集表格等场景中的“张冠李戴”问题,实现像素级结构还原。
✅ Multi-Token Prediction(MTP)与全任务强化学习:在预测当前Token时同步建模未来多个Token的概率分布,显著提升长文档语义连贯性;配合“语义+坐标”双目标优化训练,专项强化IoU定位精度,有效抑制定位幻觉,保障输出结果在物理空间与业务逻辑上的双重可信。
凭借上述技术创新,Unisound U1-OCR在多项国际权威文档智能评测中斩获SOTA成绩:
1. OmniDocBench V1.5评测SOTA:以95.1分领跑全球,大幅超越GLM-OCR、Deepseek-OCR2、Gemini-3-Pro及GPT-5.2等主流模型,展现顶尖精度与泛化能力。
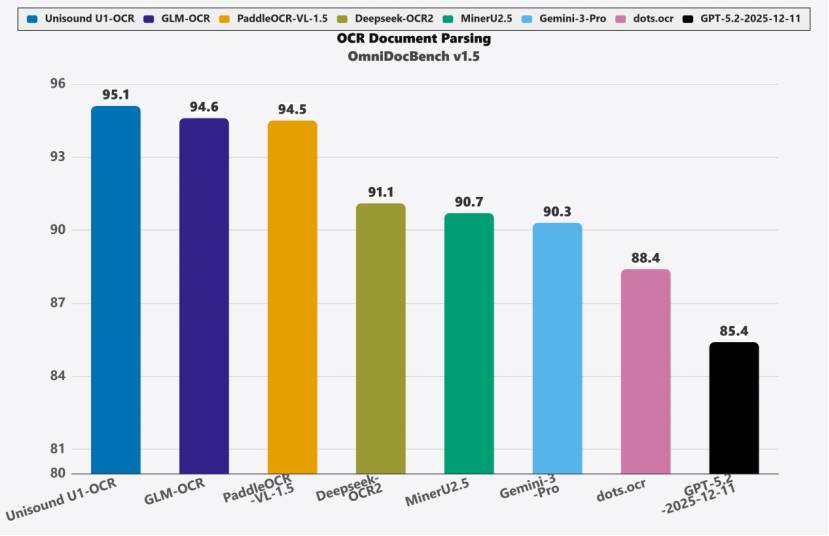
图1 Unisound U1-OCR在OmniDocBench V1.5的评测得分对比
2. D4LA评测SOTA:F1达90.8分,显著优于DocLayout-YOLO(87.3)、PP-StructureV3(86.0),支持开箱即用解析学术论文、财务报表等11类高复杂度文档,无需微调。
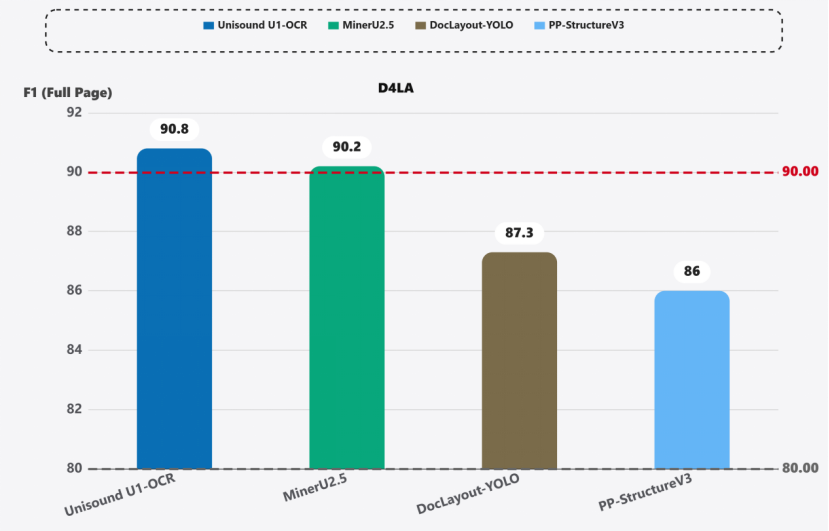
图2 基于D4LA评测的文档版面解析横向对比结果
3. DocLayNet评测SOTA:F1高达95.9分,超越MinerU 2.5、PP-StructureV3,在跨页表格关联、微小文本检测、多栏错位等高难度任务中表现尤为稳健。
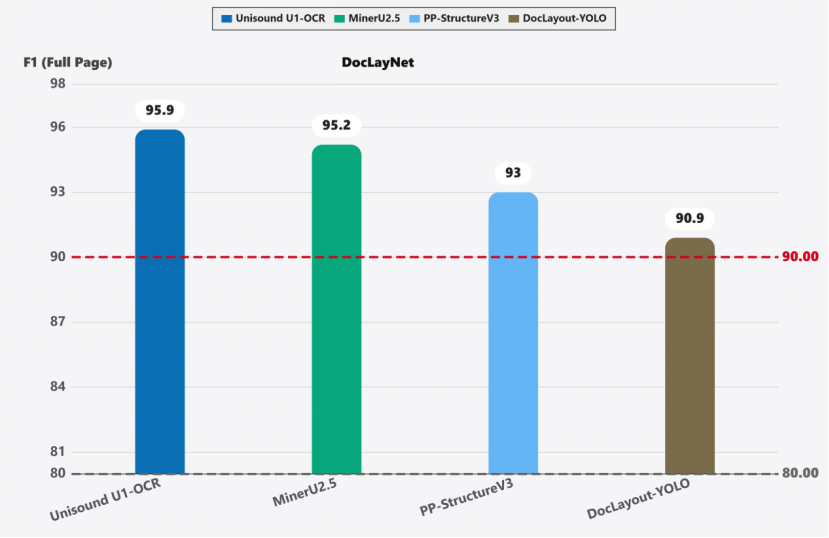
图3 基于DocLayNet评测的文档版面解析横向对比结果
4. 业务级实测SOTA:在医疗入院记录、金融合同、医保单据等真实业务数据集上,信息抽取与文书分类能力全面超越Gemini-2.5-Flash、Qwen-235B-VL等通用大模型。尤其在3B参数量级下,达成比更大规模VLM更优的业务指标,验证其“小而精、专而强”的工业适用性。
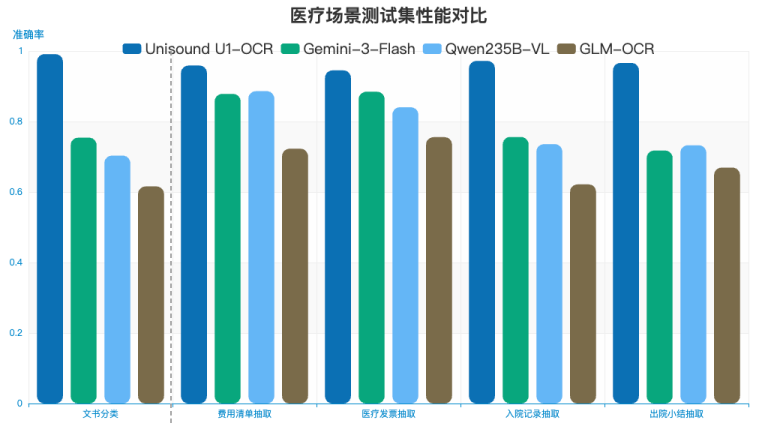
图4 基于业务数据集的文书分类和信息抽取能力横向对比评测结果
工业就绪:四大能力支撑AI从“读懂”走向“执行”
Unisound U1-OCR不仅性能领先,更深度适配企业级真实需求,打造四大落地级能力:
1. 可信可验:结果全程可溯源
独创“坐标-文本-语义”三重融合架构,每项抽取结果均附带像素级原始位置标记与证据链,支持一键高亮回溯。审核人员秒级定位原文,大幅压缩人工复核时间,真正实现“所见即所得、所用即所源”的可信AI。
2. 业务融合:Agent Ready,开箱即用
内嵌医疗、金融等领域知识规则,支持多字段语义校验(如医保单中“自付一/二”与“个人自费”的逻辑判别、合同金额大小写一致性验证)。内部测试显示,50+类常见业务文书分类准确率超99%,无需额外标注即可对接RPA或智能体工作流。
3. 高效可控:私有化部署,秒级响应
全面支持离线、私有化部署,满足政务、医疗、金融等高安全场景的数据合规要求;结合版面级并行解码与MTP架构,十余页PDF文档端到端处理仅需数秒,让工业级文档智能真正“触手可及”。
4. 全场景鲁棒:无惧复杂文档挑战
针对手机拍摄模糊、纸张弯折、水印干扰、多语言混排、非标准排版等企业高频痛点,模型均保持高精度稳定输出,彻底摆脱对“理想扫描件”的依赖。
实战验证:六大案例见证OCR 3.0落地力
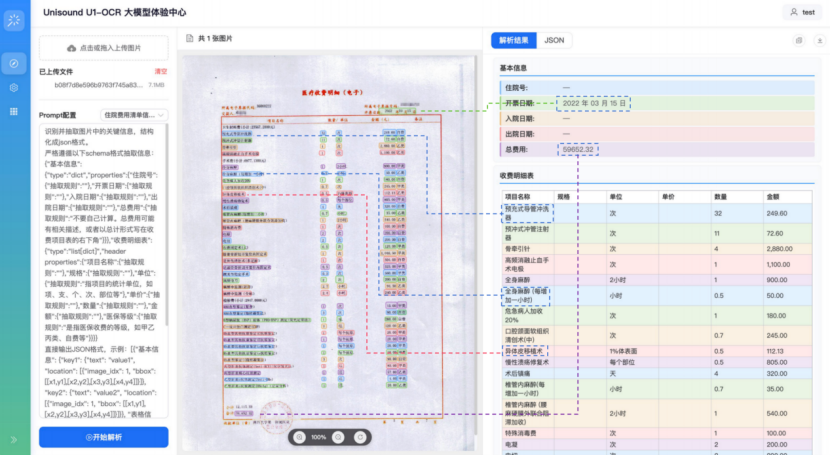
案例1|可信信息抽取:在医疗费用清单处理中,自动对齐“总计”“合计金额”等不同表述至统一字段“总费用”,并剔除干扰项直接入库;同时支持彩色坐标回溯(如图所示),实现“秒级定点确认”。
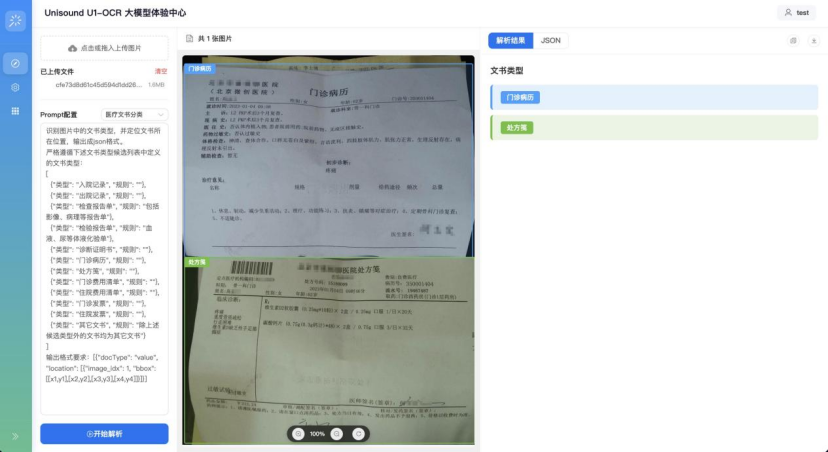
案例2|单图多文档分离:自动识别并分割混叠的病历、处方、检查报告等多类单据,无需预分类即可完成归档与结构化提取。
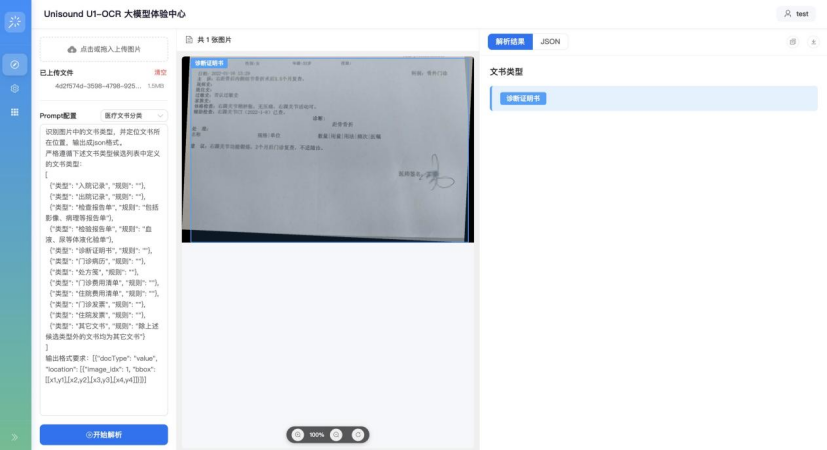
案例3|长尾场景强容错:在严重遮挡、局部缺失的非理想文档中,仍能基于深层语义推理准确判定文档类型,大幅提升自动化流程成功率。
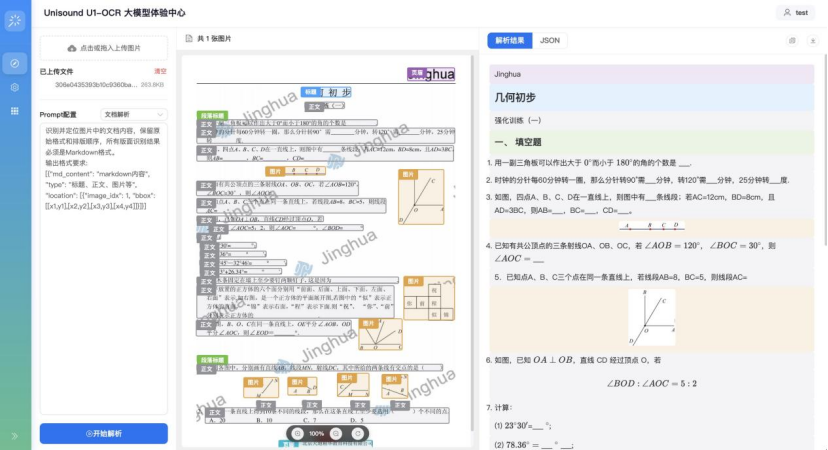
案例4|复杂版面逻辑重建:破解报纸/期刊多栏穿插难题,不再机械逐行扫描,而是结合语义与版面逻辑自动梳理符合人类阅读习惯的内容流。

案例5|智能图像净化:自动消除满屏水印、校正倾斜扭曲,输出规整、清晰、结构完整的标准化文档,为后续识别奠定高质量输入基础。
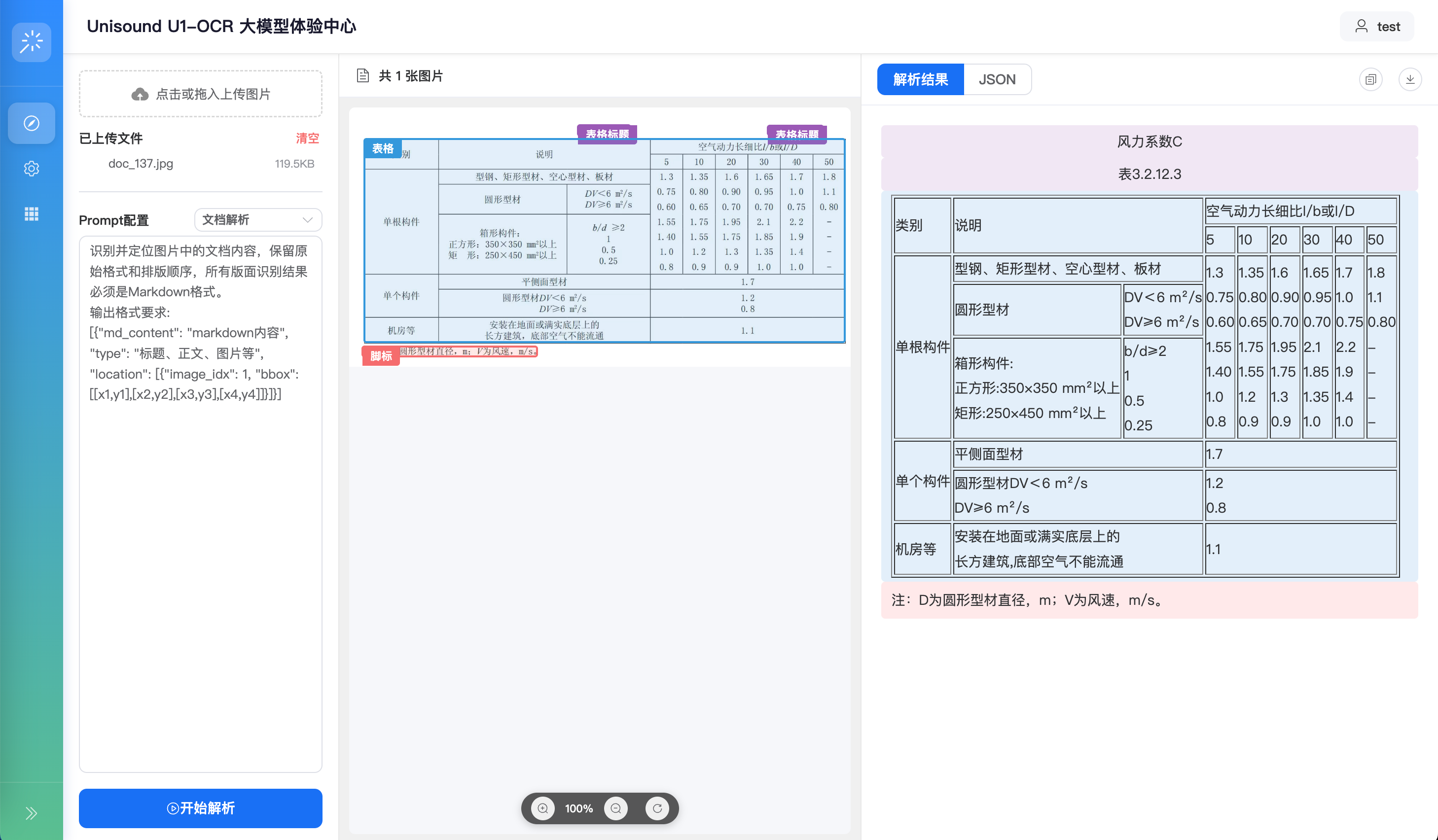
案例6|复杂表格零失真解析:精准识别跨行跨列、嵌套合并单元格,完整保留原始行列结构与逻辑关系,输出结果可直接用于统计分析或系统导入,免去人工二次调整。
Unisound U1-OCR的发布,标志着文档智能正式迈入OCR 3.0时代——AI不再止步于“识字”,而是真正具备“理解业务、遵循逻辑、追溯证据”的认知能力。这不仅是云知声在多模态AI领域的重大里程碑,更是通向AGI的重要实践路径:以文档为知识入口,构建可推理、可验证、可执行的下一代智能基础设施。