云知声发布“山海·知音”2.0:ASR首次突破90%噪声识别率,TTS支持12方言+全双工实时对话
SmartHey1月26日消息,云知声今日正式发布‘山海·知音’大模型2.0,标志着其‘一基两翼’技术战略升级迈出关键一步——以‘山海·Atlas’通用智算基座为根基,协同‘山海·知医’等垂直智能体,加速AI能力向真实生活场景深度渗透。
‘山海·知音’2.0聚焦三大核心进化:听懂专业与乡音、聊出亲情与温度、实现极致机敏反应,全面提升人机语音交互的准确性、自然度与实时性。
听懂专业与乡音——ASR全景升级
本次升级的语音识别(ASR)能力在公开测试集与云知声自建全场景测试集中均表现卓越,覆盖从日常对话到医疗问诊、方言播报、嘈杂环境等极端用例,综合性能超越国内主流开源及闭源语音大模型,达行业领先水平。
尤为突出的是,在高干扰复杂噪音与多方言口音混合场景下,识别准确率相较主流ASR模型提升2.5%–3.6%;在强背景音环境下,识别准确率首次突破90%,创下业界新标杆。
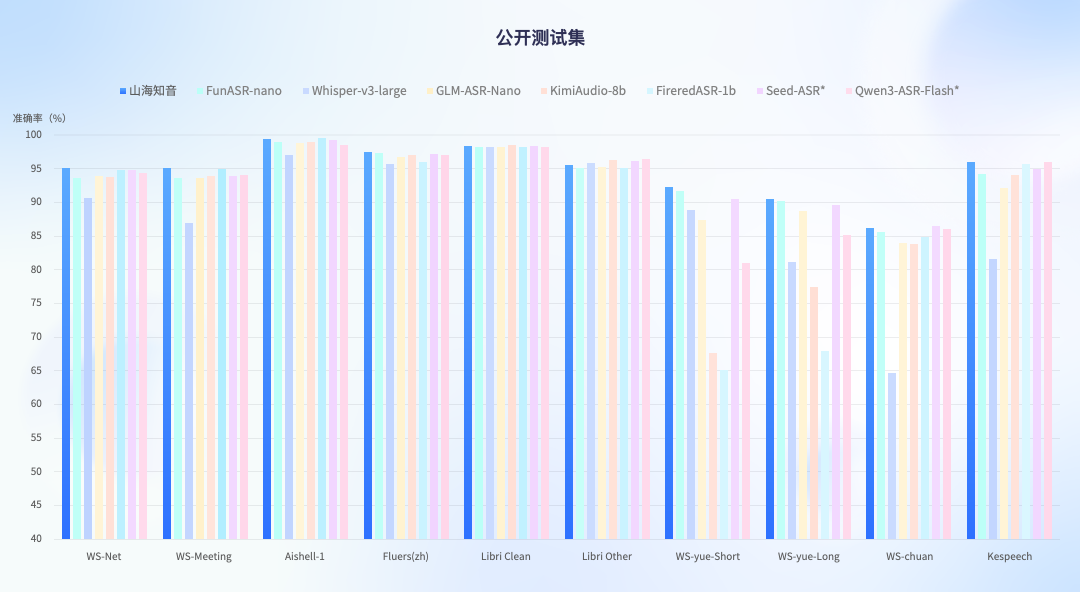
公有测试集
随着智能体时代全面到来,云知声在持续迭代‘山海·Atlas’多模态、跨语言通用基座的同时,已于年前完成‘山海·知医’5.0医疗大模型升级;此次‘山海·知音’2.0的发布,进一步补全‘一基(Atlas基座)两翼(知音交互+知医垂类)’技术拼图。
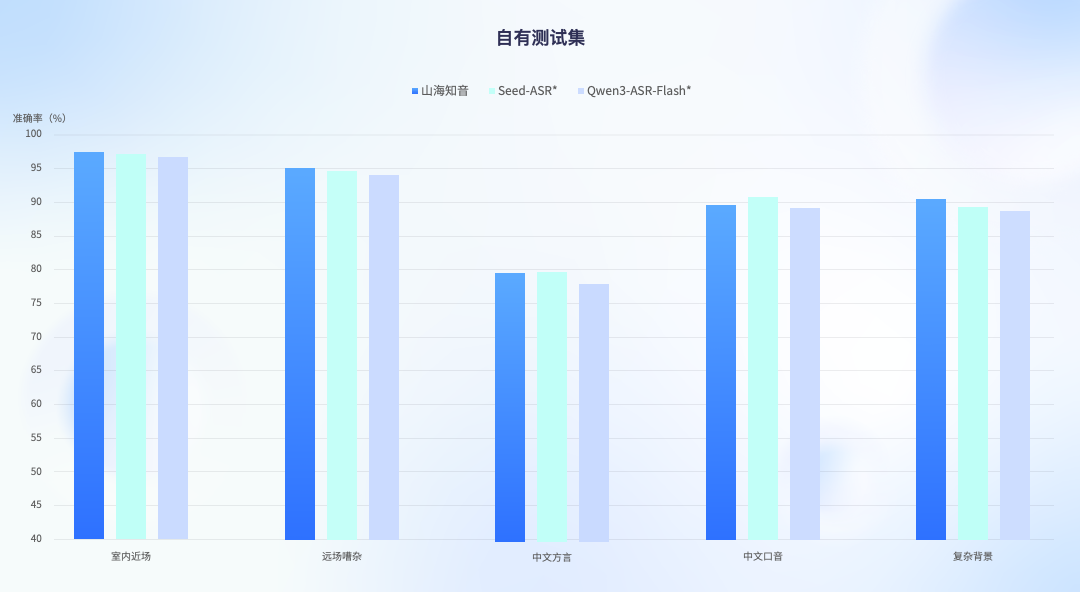
自有测试集
聊出亲情与温度——TTS声动进化
作为ASR的‘声音出口’,‘山海·知音’TTS系统以‘高度拟人化+创意表达力’为核心突破。当前已支持12种中文方言(含粤语、四川话、上海话等)及10种外语,更精细还原清嗓、轻笑、呼吸等副语言特征;普通话可切换12种风格——温柔、干练、亲切、沉稳等随需而变,真正践行‘科技不该高高在上,而该用你最舒服的方式说话’。
传统大模型驱动的TTS常采用流匹配(Flow Matching)+神经声码器两段式架构,虽保质量但延迟偏高。为兼顾高质与实时,云知声首创基于纯因果注意力机制的端到端流匹配模块,并与神经声码器联合优化,构建全链路纯流式推理架构。
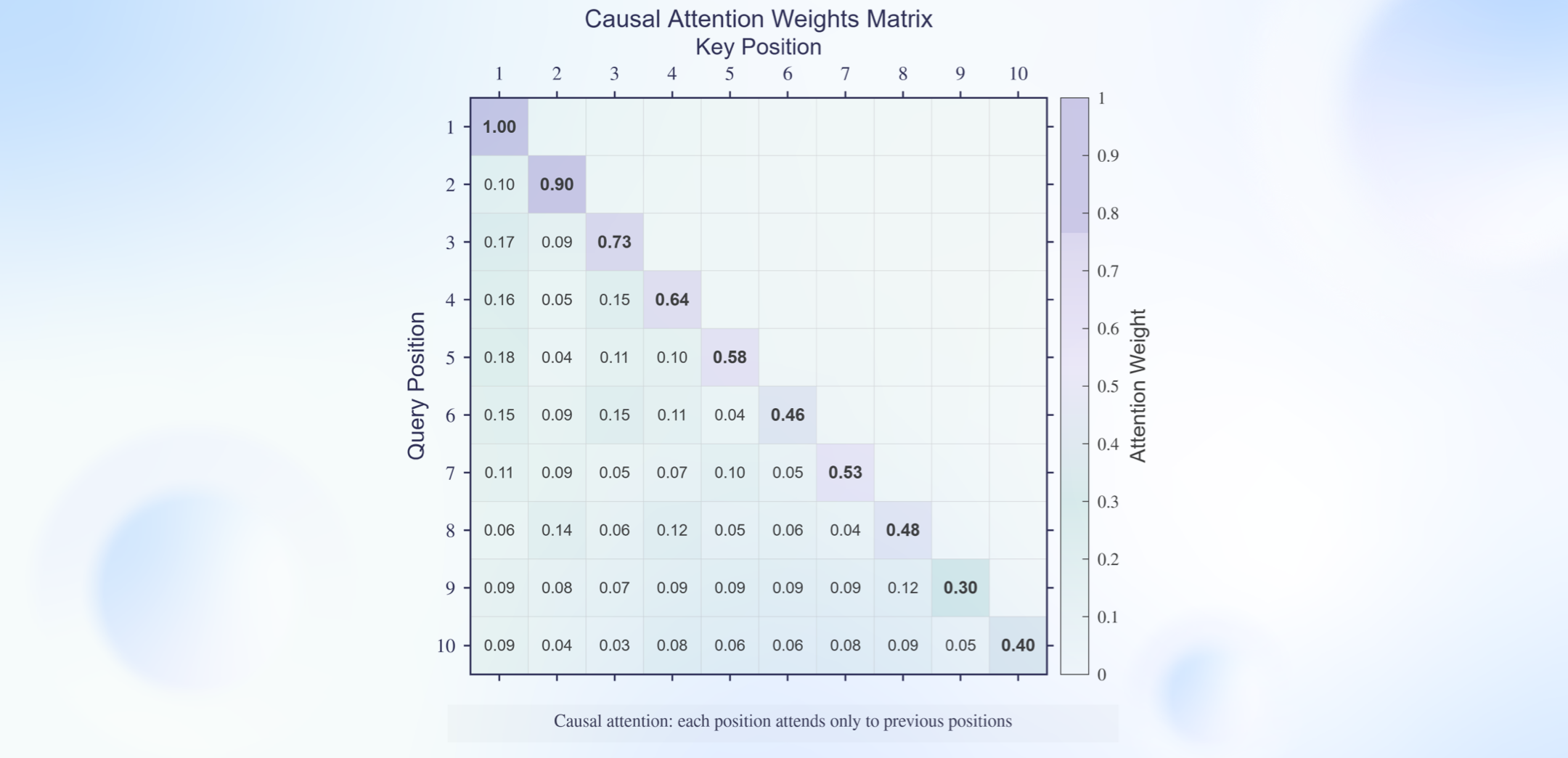
因果注意力机制
该方案在不牺牲音质前提下显著压缩延迟:低并发场景下首包响应时间压至90毫秒以内,达到人耳无感的实时交互水准,为车载、陪护、远程问诊等强交互场景提供坚实支撑。
极致机敏反应——端到端全双工交互
真正的智能对话,不止于‘答得快’,更在于‘听得懂上下文、接得住情绪变化、断得了也续得上’。‘山海·知音’2.0依托全新端到端交互大脑,攻克流式收音中同步理解、决策与生成的技术难关,实现毫秒级打断响应、无缝接话与连贯多轮追问,交互体验趋近真人对话——‘这不是问答,是对话。’
上述能力的背后,是云知声自研的‘山海·Atlas’智算一体基座:它并非简单叠加ASR/TTS/LLM模块,而是将多模态感知、语言理解、语音生成深度融合进统一端到端大模型架构,从根本上打破传统级联式系统的延迟瓶颈与语义割裂,释放出远超模块叠加的协同效能。
智起山海,知音万物。从三甲医院手术室到偏远乡村卫生站,从智能座舱到独居老人床头,云知声始终相信:AI的价值不在参数规模,而在是否真正‘听得清、说得真、懂人心’。‘山海·知音’2.0,正让人工智能卸下冰冷外壳,成为可信赖、有温度、会共情的生活伙伴——这一次,AI终于学会好好说话了。