云知声发布U2-ASR 2.5:首个中文方言语义转写大模型,实现“听清”到“听懂”的跨越
SmartHey5月13日消息,云知声今日正式推出首个中文方言语义转写大模型——U2-ASR 2.5,全面覆盖七大方言体系,支持100余种方言及地方口音识别转写,方言人口覆盖率超90%。
该模型首次打通“方言识别—语义还原—普通话表达”全链路,不仅能准确识别地域化、口语化、高度混杂的方言语音,更能深入理解其背后的真实意图,并将其转化为规范、准确、可读性强的普通话文本,真正实现AI对中文方言的深度语义理解。
在最新一轮工业级评测中,U2-ASR 2.5展现出卓越的方言识别能力:在云知声自建高难度方言测试集上,其整体表现全面领先主流ASR模型。多项代表性方言识别准确率突破90%——济南话达96.2%,四川话94.7%,粤语93.0%,武汉话92.1%,充分验证其在口音差异大、方普混说频、地域表达复杂等真实挑战场景下的领先性与鲁棒性。
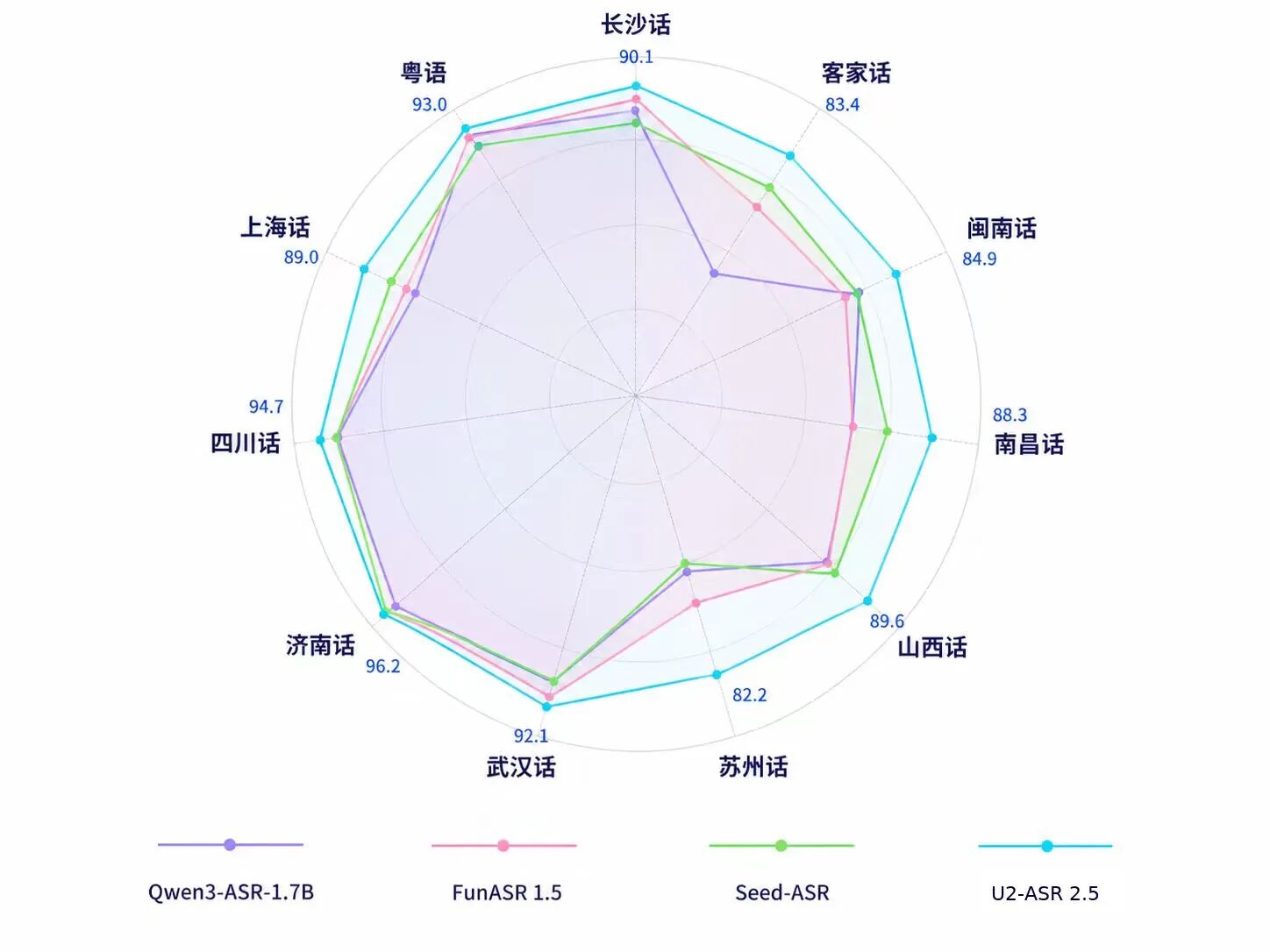
工业级测试集测试结果
与此同时,U2-ASR 2.5在通用中英文语音识别任务中同样保持顶尖水准:在AISHELL、FLEURS、LibriSpeech、WenetSpeech Meeting、KeSpeech等权威公开测试集上持续刷新成绩,其中AISHELL-1达99.2%,Libri Clean达98.4%,AISHELL-3达98.4%。这表明,其方言能力并非孤立叠加,而是构建于坚实、泛化性强的多语种语音识别底座之上。
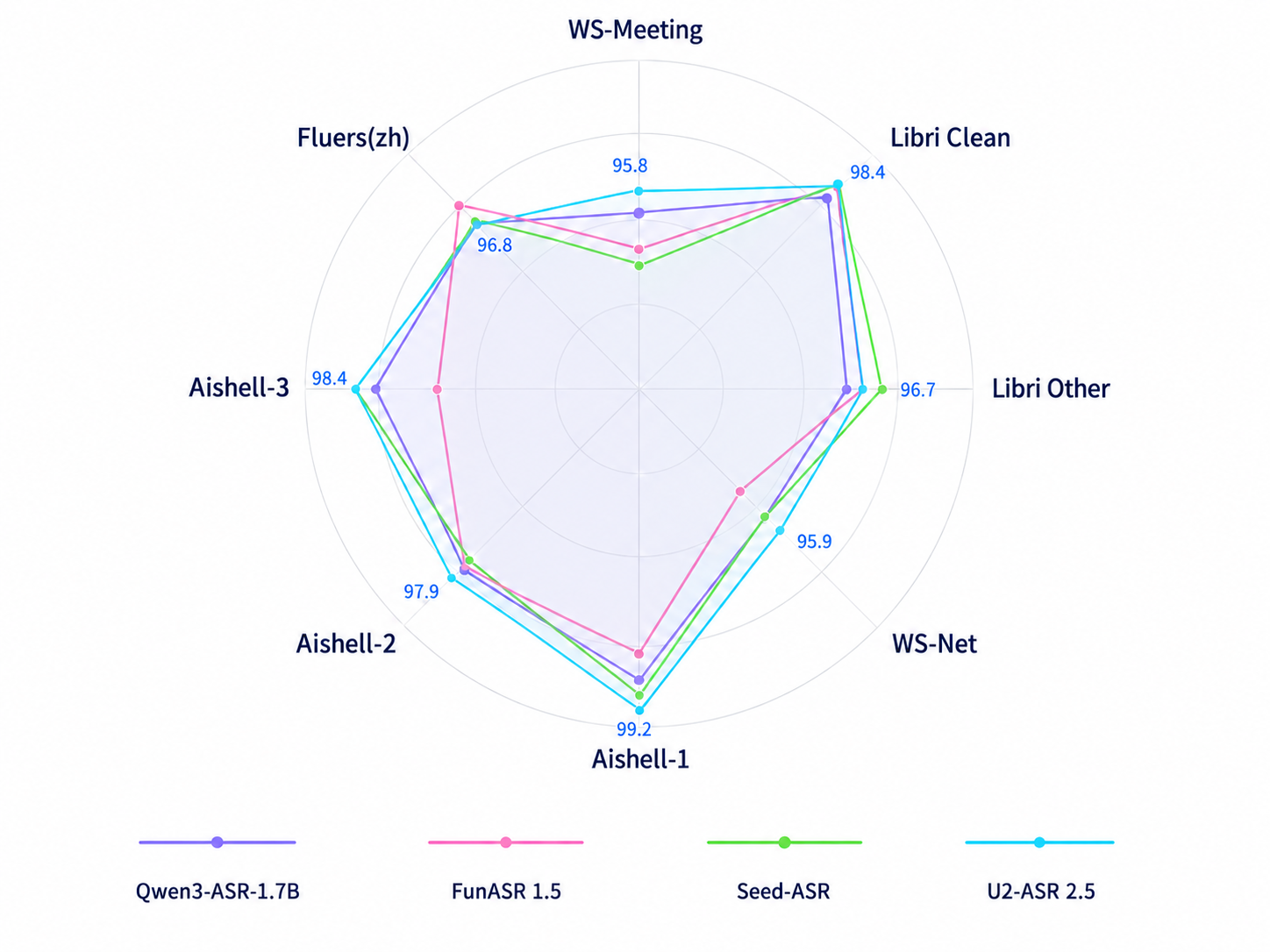
中英文公开测试集测试结果
本次升级的核心突破在于语义层能力跃升:模型新增方言词义映射、上下文意图建模与普通话语义还原模块,可将晦涩、零散、强地域性的方言表达,系统性地重构为逻辑清晰、术语规范、便于后续处理的普通话语义文本。
方言识别之难,源于其本质是非标准化的动态语言系统——同一方言在不同年龄、地域、语境下发音、用词、语法均存在显著差异;同一词汇,在各地可能音异、形异、义异。叠加设备噪声、语速突变、多人交叠、方普混用等现实干扰,方言ASR早已超越简单语音转文字,演变为一项融合声学建模、语言理解与工程落地的综合性语音认知工程。
为此,U2-ASR 2.5围绕数据构建、解码优化与语义理解三大关键路径,完成系统性升级:在数据层面,针对方言样本分散、录音条件不一、转写标准缺失等痛点,构建高质量、多场景、强标注的工业级方言语料库;在工程层面,打造覆盖前端信号增强、模型热词适配、流式推理加速、后端语义纠错的全链路工业级部署体系,确保模型不仅“测得高”,更能“跑得稳、用得久”。
高识别率:不止于准确,更胜于稳定
方言识别的终极目标,是在真实复杂输入中稳定捕捉用户意图。U2-ASR 2.5持续拓展能力边界,覆盖官话、晋语、吴语、湘语、赣语、闽语、客家话、粤语等主要汉语方言体系,在南北多区域、多语系、多口音场景中展现更强泛化力与一致性,综合识别性能显著优于行业主流方案。
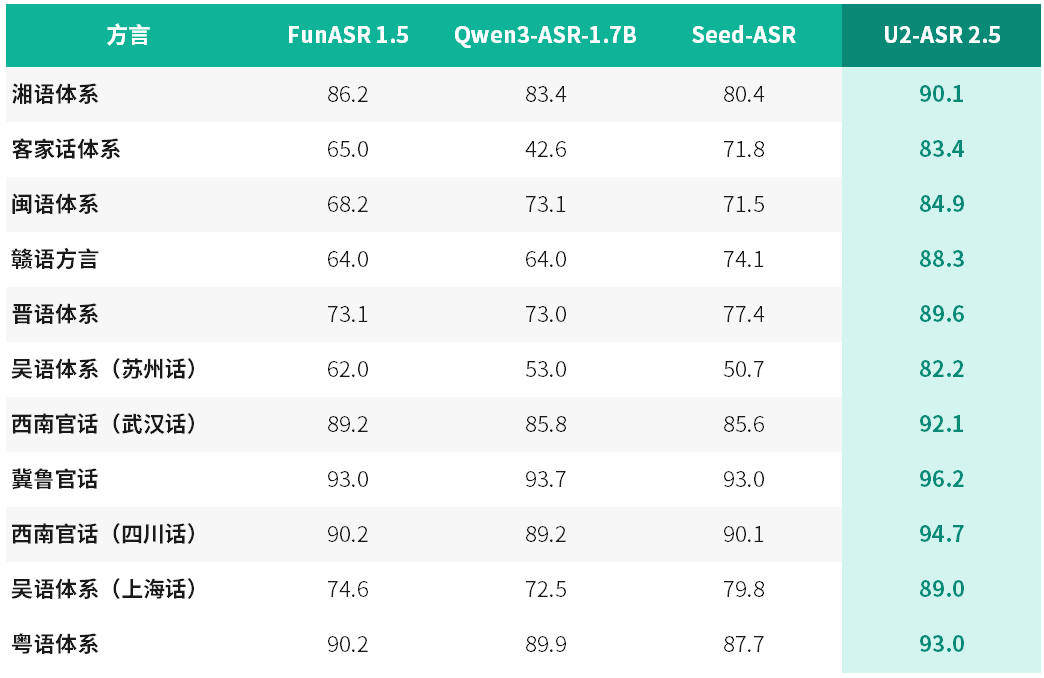
工业级测试集测试结果
其在AISHELL、LibriSpeech、FLEURS等中英文基准测试中的持续优异表现,进一步印证了其通用语音能力与方言专项能力的深度融合与协同进化。
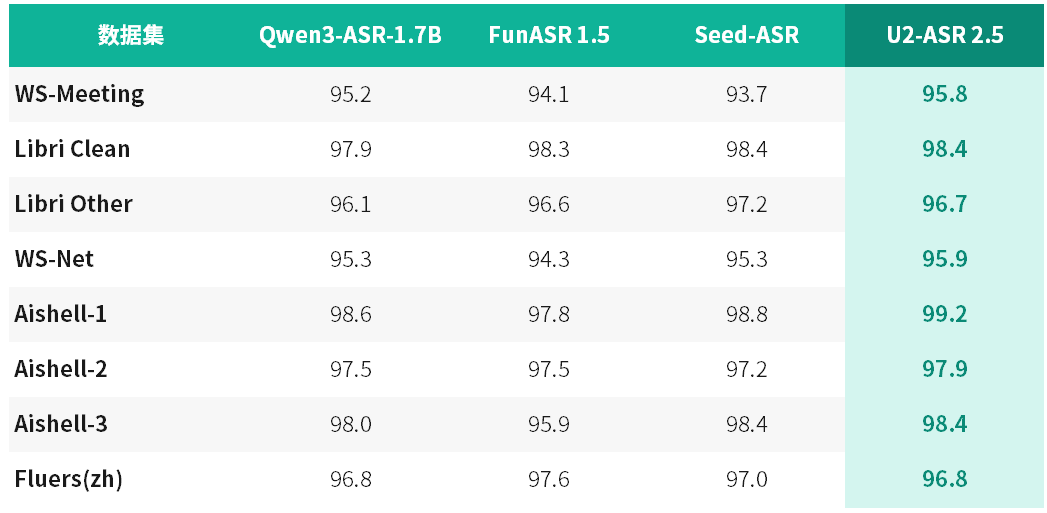
中英文公开测试集测试结果
这意味着,U2-ASR 2.5正推动方言语音识别从“实验室高分”迈向“真实世界好用”,让技术真正适配中国最丰富、最生动的语言生态。
高噪识别:听得懂烟火气,也听得懂急迫感
真实语音场景从非理想环境:夜市喧嚣、医院嘈杂、政务大厅人声鼎沸……传统模型常因噪声压制过度或端点误判导致漏识、错断、语义割裂。U2-ASR 2.5在语音预处理阶段集成多通道智能降噪、自适应回声消除与非稳态噪声建模技术,在最大限度保留有效语音特征的同时抑制干扰;结合鲁棒性声学建模与精准端点检测,显著提升复杂声学环境下的识别稳定性与连贯性。
专业增强:听得懂方言,更听得懂业务
在医疗问诊、政务办理、金融理赔等垂直场景中,用户表达常夹杂大量专业术语、机构名称与业务关键词。U2-ASR 2.5支持热词动态注入、行业词表在线适配与领域语义强化,可针对医疗病症、政务流程、保险条款等高频业务实体进行定向识别增强,大幅降低关键信息误识率,实现“语言理解”与“业务理解”的双轨并进。
低延迟响应:快而准,稳而实
通过模型量化压缩、算子融合优化、流式解码架构升级与服务端并发调度策略,U2-ASR 2.5显著降低推理时延与资源开销;同时引入重打分机制与细粒度纠错模块,对人称代词混淆、语气助词冗余、口语省略等典型问题进行语义级校验与修正,保障输出结果既高效、又精准、更可用。
落地场景:让技术有温度,让服务更自然
在中国,方言是数亿人最自然、最亲切的日常表达方式。尤其在适老化服务、基层政务、基层医疗等关键民生场景中,语言习惯差异仍可能成为信息传递与服务体验的隐性门槛。
智慧政务:在社区窗口、便民终端等一线场景,群众倾向使用方言表达诉求。U2-ASR 2.5可实时将方言语音转化为结构化、可处理的普通话文本,减少重复确认,提升政策传达与事务办理效率,助力公共服务“无感接入、有感体验”。
智慧医疗:面对患者主诉中的口音混杂、表达模糊、术语混用等问题,模型凭借抗噪能力与医疗热词增强,可精准捕获症状描述、病史关键词与用药反馈,辅助医生高效记录、准确判断,降低沟通误差带来的诊疗风险。
智慧金融保险:在理赔咨询、保全服务等环节,用户常以方言+口语+专业术语混合表达。U2-ASR 2.5可稳定提取疾病名称、赔付范围、费用明细等核心要素,并完成语义规范化,为材料审核、风险评估与服务追溯提供高可信文本支撑。
智慧客服:面向方言高频区域的热线、外呼、坐席系统,模型支持自然方言交互,无需用户刻意切换语言,显著缩短交互路径,提升首呼解决率与用户满意度。
文旅与内容创作:在地方纪录片制作、非遗口述采集、文旅宣推等工作中,海量原生方言素材长期面临整理难、检索难、传播难问题。U2-ASR 2.5可将其高效转化为可编辑、可索引、可分析的标准文本,赋能地方文化数字化保护与创新表达。
每一种方言,都是一套完整的意义系统,承载着一方水土的生活经验与文化记忆。理解方言,不仅是解码声音,更是读懂语境、共情表达、抵达意图。U2-ASR 2.5的发布,标志着云知声正从“语音识别”迈向“语音认知”,从“听清”走向“听懂”。
未来,云知声将持续深化方言语音技术演进,拓展地域覆盖广度、场景适配深度与人群服务温度,让AI真正听懂每一个中国人最本真的表达。
目前,包含U2-ASR、U2-TTS、U2-TTS-Clone在内的“山海·知音”系列模型已全面上线云知声Token Hub大模型服务平台,开放标准化API接口,支持一键接入、按需调用、按Token计费,兼顾灵活性与可控性。