豆包大模型正式升级至2.0:Pro/Lite/Mini/Code四版本齐发,多模态与Agent能力达SOTA
SmartHey2月14日消息,今天,豆包大模型正式迈入2.0时代。
随着Agent技术深度融入现实场景,大模型正从‘理解世界’迈向‘参与并改造世界’。豆包2.0(Doubao-Seed-2.0)聚焦大规模生产环境下的实际需求,系统性强化高效推理、多模态感知与复杂指令执行能力,显著提升在真实世界中完成长链路、高不确定性任务的可靠性与实用性。
豆包2.0系列涵盖Pro、Lite、Mini三款通用Agent模型及专属Code模型,形成覆盖全场景的智能体模型矩阵:
豆包2.0 Pro专为深度推理与长程任务设计,综合能力全面对标GPT-5.2与Gemini-3-Pro;
2.0 Lite在性能与成本间取得更优平衡,整体表现超越上一代主力模型豆包1.8;
2.0 Mini面向低延迟、高并发及成本敏感型应用,兼顾响应速度与资源效率;
Code版(Doubao-Seed-2.0-Code)深度适配编程工作流,与AI编程平台TRAE协同可释放更强开发效能。
目前,豆包2.0 Pro已全面上线豆包App、桌面端及网页版,用户开启「专家」模式即可体验;豆包2.0 Code已作为核心模型集成至TRAE中国版;面向企业与开发者,火山引擎同步开放全系列豆包2.0模型API服务。
多模态理解能力跃升至行业前沿,多项基准测试刷新SOTA纪录
豆包2.0重构多模态架构,在视觉推理、空间理解、动态感知与长上下文建模等关键维度实现突破。其视觉理解能力在主流评测中普遍达到世界领先水平,其中豆包2.0 Pro在多数权威基准上斩获最高分。
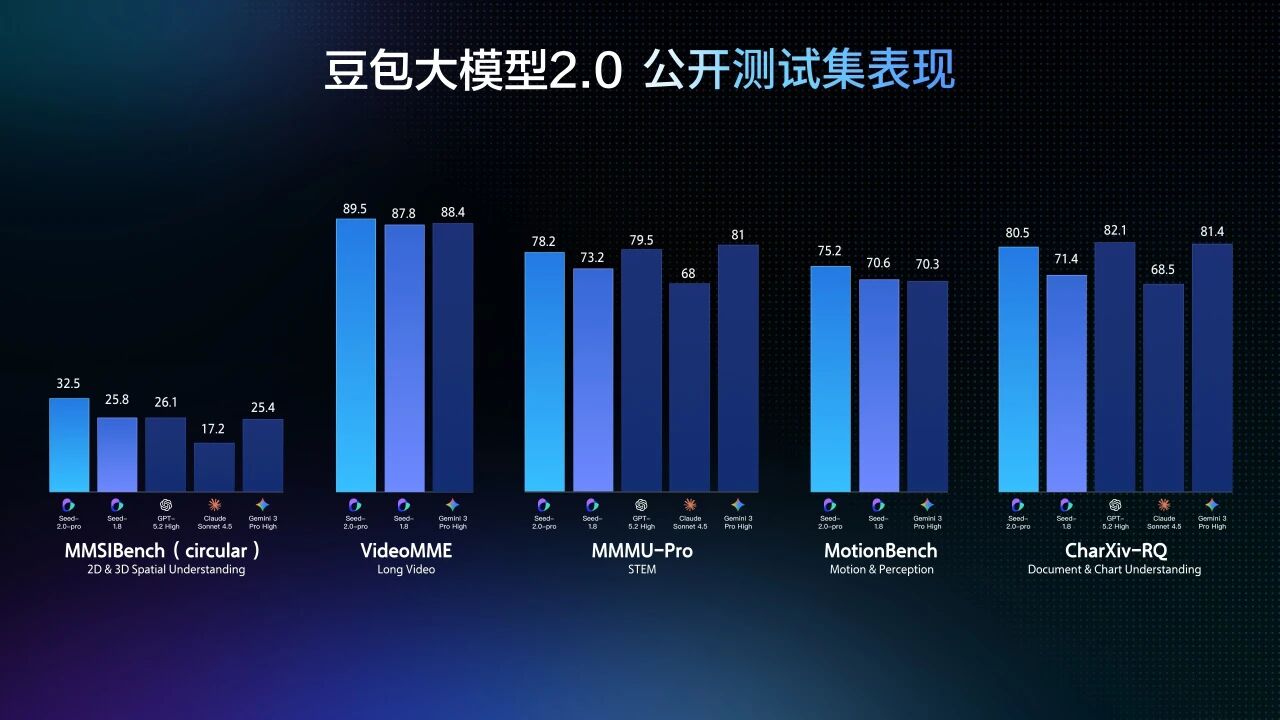
针对视频流等动态场景,豆包2.0显著增强时间序列建模与运动语义捕捉能力——在TVBench等关键测评中稳居第一梯队,并在EgoTempo基准上首次超越人类平均分,验证其对“变化节奏、动作逻辑、时序因果”的稳定建模能力,工程落地可靠性大幅提升。
在长视频分析场景中,豆包2.0不仅在多项评测中超越GPT-5.2、Gemini-3-Pro等竞品,更在流式实时问答类基准中表现突出,支持实时视频流解析、环境动态感知、主动错误修正及情感化交互,推动AI助手从“被动应答”升级为“主动陪伴与指导”,已在健身教学、穿搭建议等生活化场景中验证实用价值。
LLM基础能力与Agent执行力双突破,长程任务完成率显著提升
为支撑真实世界的复杂任务执行,豆包2.0 Pro大幅扩充长尾领域知识覆盖,尤其在专业垂直领域表现亮眼:SuperGPQA得分超越GPT-5.2;HealthBench斩获榜首;科学类综合能力与Gemini-3-Pro、GPT-5.2旗鼓相当。
在高阶推理与Agent能力评测中,豆包2.0 Pro于IMO、CMO国际数学奥赛及ICPC编程竞赛模拟测试中均摘得金牌;在Putnam Bench上超越Gemini-3-Pro;在被誉为“人类终极考试”的HLE-text评测中以54.2分刷新纪录;工具调用准确率与指令遵循鲁棒性亦处于业界第一梯队。
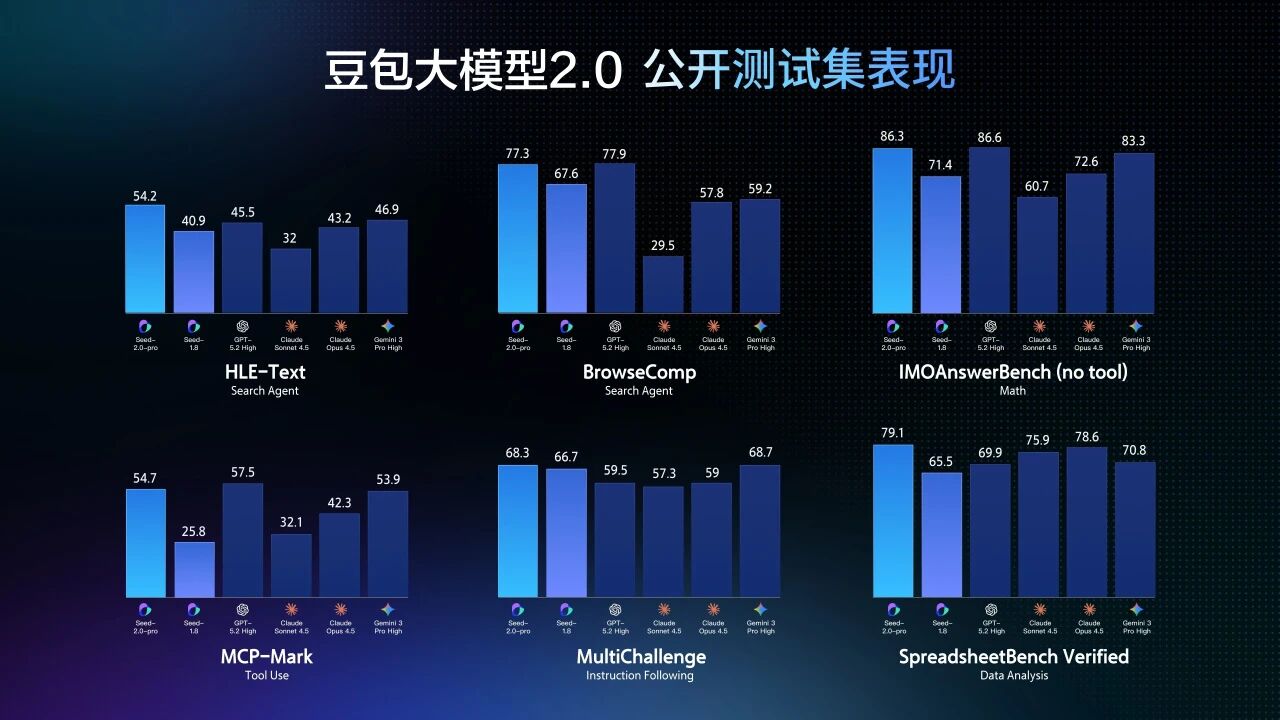
值得一提的是,豆包2.0在保持顶尖性能的同时显著优化推理成本:token单价较同类顶级模型降低约一个数量级。在需高频调用、长链生成的真实业务中(如智能客服、自动化报告生成),这一成本优势将转化为可观的规模化落地效益。
Code模型加速AI原生开发,1轮提示即可构建复杂交互应用
豆包2.0 Code基于2.0基座深度定制,重点增强代码库语义理解、跨文件逻辑推演与应用级生成能力,并显著提升Agent工作流中的自我纠错与迭代调试能力。
该模型已作为TRAE中国版默认内置模型上线,原生支持图像输入与多模态编程辅助。
以「TRAE春节小镇·马年庙会」互动项目为例——该场景涉及UI动效、事件驱动、音画同步与用户行为追踪等多项复杂需求。借助TRAE+豆包2.0 Code组合,仅需1轮高质量提示词即可生成完整项目骨架与核心逻辑,经5轮迭代调试即可交付可运行成果,极大缩短AI原生应用开发周期。
字节跳动官方表示,豆包大模型2.0系列的发布,标志着其技术路线正式锚定“真实世界复杂任务”这一核心战场。未来将持续深耕场景驱动的模型进化,拓展智能体在物理世界与数字世界的协同边界。