DeepSeek发布OCR新模型DeepSeek-OCR 2:引入‘视觉因果流’,阅读顺序准确率显著提升
SmartHey1月27日消息,DeepSeek 今日正式发布其新一代文档识别模型 DeepSeek-OCR 2。该模型在前代 DeepSeek-OCR 基础上深度优化,核心升级聚焦于视觉编码器架构的重构与语义理解能力的跃迁。
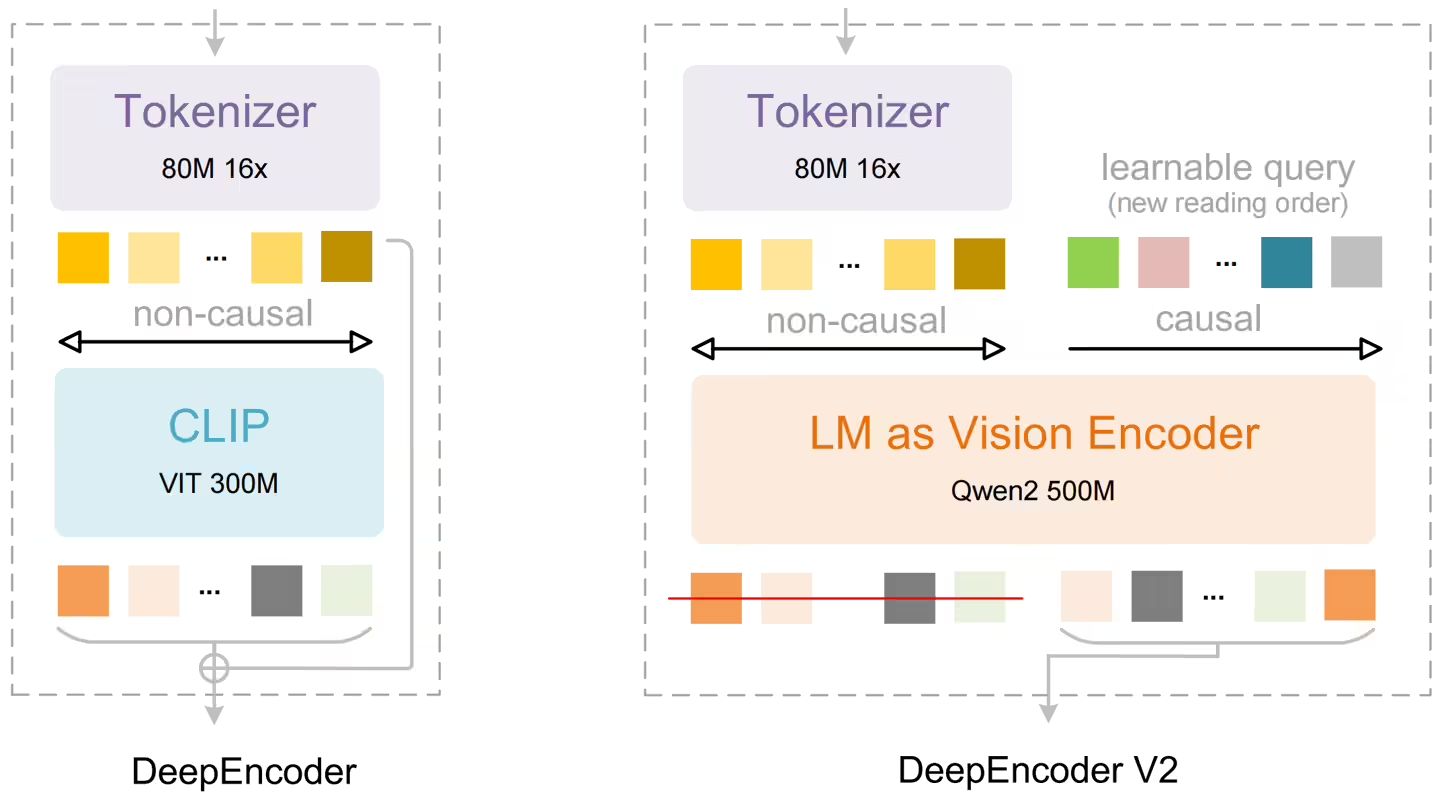
研究团队自主研发了名为 DeepEncoder V2 的新型视觉编码器。其关键创新在于支持**语义驱动的动态视觉信息排序**——模型可在文字识别前,依据图像内容的逻辑关系智能重排视觉处理顺序,使机器更贴近人类“先看标题、再扫图表、后读正文”的自然阅读范式。
传统视觉语言模型通常将图像均匀切分为固定栅格式的视觉 token,并按从左到右、从上到下的空间顺序输入模型。这种机械式流程虽易于实现,却难以应对真实文档中复杂的版式结构(如多栏排版、嵌入图表、跨页表格或数学公式),也违背人类基于语义优先级进行跳跃式浏览的认知习惯。
DeepSeek 指出,在学术论文、财报、技术手册等高复杂度文档中,视觉元素之间普遍存在明确的逻辑依赖与阅读先后关系。仅依赖空间位置建模,会严重制约模型对文档深层结构的理解能力。
为此,DeepSeek-OCR 2 首次在 OCR 领域引入“**视觉因果流**”(Visual Causal Flow)概念。DeepEncoder V2 以类语言模型结构取代原有基于 CLIP 的编码模块,并内置可学习的“因果流查询 token”。编码器融合双向注意力(用于全局视觉感知)与因果注意力(用于渐进式语义排序)双机制:前者捕获整体布局特征,后者驱动查询 token 逐步建立符合逻辑的视觉 token 序列。最终,仅经因果重排后的精简查询序列进入解码阶段,大幅提升结构建模效率。
在整体框架上,DeepSeek-OCR 2 延续了成熟的编解码范式:编码器先将原始图像压缩为紧凑的视觉 token 集合,再由 DeepEncoder V2 进行语义建模与顺序重组;解码端则采用基于混合专家(MoE)架构的语言模型,兼顾精度与推理效率。
论文显示,该设计在控制计算开销方面表现优异——单页文档所用视觉 token 数量稳定维持在 256 至 1120 区间,与前代及主流竞品保持相当的资源占用水平。
性能验证采用权威多任务基准 OmniDocBench v1.5,覆盖中英文学术论文、期刊、企业报告等真实场景文档,全面评估文本识别、公式解析、表格结构还原及**阅读顺序合理性**等核心指标。
测试结果表明,在视觉 token 上限更低的约束下,DeepSeek-OCR 2 综合得分达 91.09%,较前代提升 3.73%;其中阅读顺序准确率显著增强,编辑距离由 0.085 降至 0.057,印证其对文档逻辑结构的理解能力取得实质性突破。
实际部署效果同样亮眼:在线用户日志图像重复率由 6.25% 降至 4.17%,批量处理 PDF 的重复率从 3.69% 降至 2.88%。这意味着模型在高压缩率前提下,输出更稳定、冗余更少,大幅提升了工业级 OCR 系统的鲁棒性与可用性。